
Introduction
InfluxDB v2 beta est là. Lorsqu’on est habitué aux versions 1.x, beaucoup de changements dans la version 2. Pour plus d’informations à propos d’InfluxDB v.7 : Architecture, installation et utilisation d’une base de données Time Series InfluxDB 1.7
La procédure de migration des versions 1.x vers la version 2 n’est pas encore dévoilée, mais très probablement elle préconisera des méthodes d’export/import.
Première chose à savoir: une base de données dans InfluxDB v1 est maintenant un bucket (compartiment) dans InfluxDB version 2 et une organisation est obligatoirement associée à un bucket.
- L’index TSI est le moteur de stockage par défaut, l’index In-Memory est supprimé.
- Chronograf (outil de visualisation) est intégré dans InfluxDB.
- Flux devient le langage par défaut et InfluxQL est malheureusement supprimé.
- Les "Continuous queries" sont remplacées par les "Tasks".
- Le support natif des protocoles OpenTSDB, Graphite, CollectD… est aussi malheureusement supprimé dans InfluxDB v2, les agents Telegraf doivent être mis en œuvre.
La migration va nécessiter des ajustements, de nombreuses fonctionnalités d’InfluxDB v1 sont remplacées dans la version 2.
Installation
Il s’agit d’une installation "non-root", les binaires Linux 64 bits de la version 2.0 beta 2 sont téléchargés depuis le site web d’InfluxDB.
L’installation est réalisée avec le user influxdb dans le répertoire /opt/influxdata/influxdb-2.0-beta2.
influxdb% cd /opt/influxdata
influxdb% wget https://dl.influxdata.com/influxdb/releases/influxdb_2.0.0-beta.2_linux_amd64.tar.gz
influxdb% mkdir influxdb-2.0-beta2
influxdb% tar xvzf influxdb_2.0.0-beta.2_linux_amd64.tar.gz -C influxdb-2.0-beta2 --strip-components 1
influxdb% ln -fs influxdb-2.0-beta2 influxdb-2.0Un lien symbolique influxdb-2.0 pointant sur le répertoire influxdb-2.0-beta2 est créé
pour faciliter la gestion des versions.
Dans la version 2 beta 2, juste 2 exécutables installés dans ce répertoire : le serveur influxd et le client influx.
Il n’y a pas (encore ?) de fichier de configuration.
Des variables d’environnement pratiques sont créées et le chemin vers les binaires InfluxDB v2 est
ajouté dans la variable d’environnement $PATH :
influxdb% export IFXHOME=/opt/influxdata/influxdb-2.0
influxdb% export IFXSRVNAME=srvifx2
influxdb% export LOG=/opt/influxdata/dba/${IFXSRVNAME}/log
influxdb% export SCRIPTS=/opt/influxdata/dba/${IFXSRVNAME}/scripts
influxdb% export PATH=${IFXHOME}:$PATHInitialisation
Initialiser la base de données avec les options bolt-path et engine-path.
Ces 2 options vont respectivement personnaliser la localisation de la base "bolt" et de la base de données du moteur,
sinon elles sont créées dans le répertoire $HOME/.influxdbv2.
influxdb% nohup influxd --bolt-path=/sqlpac/influxdb/${IFXSRVNAME}/srvifx2.bolt \
--engine-path=/sqlpac/influxdb/${IFXSRVNAME} \
--http-bind-address=":9999" >> $LOG/srvifx2.log 2>&1 &Les buckets Time series seront stockés dans le répertoire --engine-path.
Une nouvelle base de données "bolt" est créée avec la version 2 (--bolt-path) :
elle stockera les users, organisations, tokens de sécurité, autorisations, tâches, définitions des tableaux de bords, endpoints…
Dans la version 2 beta 2, le port par défaut est pour le moment le port 9999 afin de ne pas interférer avec les serveurs InfluxDB v1.x existants sur le port 8086.
L’outil de visualisation intégré sera plus exploité avec la version 2 que Chronograf dans la version 1 en raison de la complexité du langage Flux, difficile à apprendre, aussi SSL devrait être implémenté, ce point sera discuté plus tard.
L’installation n’est pas encore terminée, le bucket, l’organisation et l’utilisateur par défaut doivent être initialisés.
Choisir avec précaution ces valeurs. Lancer influx setup pour initialiser :
influxdb% influx setupWelcome to InfluxDB 2.0! Please type your primary username: dba Please type your password: Please type your password again: Please type your primary organization name: sqlpac Please type your primary bucket name: masterts Please type your retention period in hours. Or press ENTER for infinite.: You have entered: Username: dba Organization: sqlpac Bucket: masterts Retention Period: infinite Confirm? (y/n): y Your token has been stored in /opt/influxdata/.influxdbv2/credentials. User Organization Bucket dba sqlpac masterts
Un token (ou jeton) est créé dans le fichier $HOME/.influxdbv2/credentials (/opt/influxdata/.influxdbv2/credentials).
Conserver et sauvegarder ce token, il s’agit du token de l’administrateur.
Utilisation du client influx
Les commandes shell InfluxQL ne sont plus disponibles (SHOW DATABASES, CREATE DATABASE…).
Le client influx doit être invoqué avec des paramètres.
Gestion des Buckets
Pour lister les buckets (l’organisation est requise) :
influxdb% influx bucket find --org sqlpacID Name Retention OrganizationID df913a2a0974f86a masterts 0s e71686ff910f3f32 000000000000000a _tasks 72h0m0s 000000000000000b _monitoring 168h0m0s
La base de données système 1.x _internal n’existe plus. Avec la version 2, deux buckets systèmes : _tasks
et _monitoring.
Pour créér un bucket :
influxdb% influx bucket create --org sqlpac --name netdatatsdbID Name Retention OrganizationID 5b65ed72bde3059b netdatatsdb 0s e71686ff910f3f32
La rétention par défaut est infinie, une rétention peut être définie lors de la création d’un bucket :
influxdb% influx bucket create --org sqlpac --name telegraf --retention 48hID Name Retention OrganizationID 1551723bb12b1b41 telegraf 48h0m0s e71686ff910f3f32
La rétention peut être modifiée plus tard (malheureusement dans certaines commandes l’id doit être spécifié et non le nom) :
influxdb% influx bucket update --id 1551723bb12b1b41 --retention 72hID Name Retention OrganizationID 1551723bb12b1b41 telegraf 72h0m0s e71686ff910f3f32
Les variables d’environnement $INFLUX_%
La plupart des commandes requièrent en arguments un nom ou id d’organisation, un nom de bucket name… Des variables d’environnement facilitent l’utilisation des
commandes influx :
influxdb% export INFLUX_ORG=sqlpac influxdb% influx bucket findID Name Retention OrganizationID 1551723bb12b1b41 telegraf 72h0m0s e71686ff910f3f32 5b65ed72bde3059b netdatatsdb 0s e71686ff910f3f32 df913a2a0974f86a masterts 0s e71686ff910f3f32
Les variables d’environnement suivantes peuvent être définies :
$INFLUX_ORG |
Nom de l’organisation |
$INFLUX_BUCKET_NAME |
Nom du Bucket |
$INFLUX_TOKEN |
Token à utiliser si ce n’est pas celui de l’administrateur (fichier $HOME/.influxdbv2/credentials) |
$INFLUX_HOST |
Le hostname InfluxDB si ce n’est pas celui par défaut (http://localhost:9999).
Cette variable est exploitée lors du passage en https/ssl. |
Users et autorisations
InfluxDB v2 offre une meilleure gestion de la sécurité et des autorisations, tout est stocké dans la base bolt :
Pour créer un user :
influxdb% influx user create --name telegraf --org sqlpac --password "*************"ID Name Organization ID 0539a982fcd5d000 telegraf e71686ff910f3f32
Les autorisations sont ensuite définies pour le user, dans l’exemple ci-dessous, le user telegraf
est autorisé en lecture/écriture dans les buckets de son organisation :
influxdb% influx auth create --user telegraf --read-buckets --write-bucketsID Token Status UserID Permissions 0539aad15315d000 TXds8JZO0El46vybQROsjqsaM44fkLg_ghm6V6dkLxzYIyzey-cDKzaE7TLVUQUvwosidjkt9DPrMH8zSKGitA== active 0539a982fcd5d000 [read:orgs/e71686ff910f3f32/buckets write:orgs/e71686ff910f3f32/buckets]
Le token est important, il sera utilisé pour la connexion au serveur InfluxDB avec les droits appropriés.
De nombreuses autorisations peuvent être définies (reads/writes sur les buckets, dashboards, tasks …) : utiliser influx auth create --help pour
la liste complète.
influxdb% influx user findID Name 053998e902d5d000 dba 0539a982fcd5d000 telegrafinfluxdb% influx auth findID Token Status User UserID Permissions 053998e91e55d000 kG0… active <nil> 053998e902d5d000 [read:authorizations write:authorizations read:buckets write:buckets read:dashboards write:dashboards read:orgs write:orgs read:sources write:sources read:tasks write:tasks read:telegrafs write:telegrafs read:users write:users read:variables write:variables read:scrapers write:scrapers read:secrets write:secrets read:labels write:labels read:views write:views read:documents write:documents read:notificationRules write:notificationRules read:notificationEndpoints write:notificationEndpoints read:checks write:checks] 0539ada78c95d000 8on… active <nil> 0539a982fcd5d000 [read:orgs/e71686ff910f3f32/buckets write:orgs/e71686ff910f3f32/buckets]
Lecture des séries
La traduction des requêtes InfluxQL vers le langage Flux n’est pas évidente, de plus, note importante : un intervalle de temps est désormais obligatoire dans le langage Flux, sinon la requête échoue avec l’erreur ci-dessous :
Error: Failed to execute query: compilation failed: cannot submit
unbounded read to "netdatatsdb"; try bounding 'from' with a call to 'range'.| InfluxQL | Flux |
|---|---|
|
|
Pour apprendre le langage Flux, les 2 publications ci-dessous peuvent aider :
- SQLPAC - InfluxDB v2 : langage Flux, aide-mémoire
- SQLPAC - InfluxDB, Passer du langage InfluxQL au langage Flux
Utiliser influx avec l’option query et donner le chemin vers le script Flux, donner les commandes Flux en une
seule ligne de commandes est trop ardue :
$SCRIPTS/script1.flux
from(bucket: "netdatatsdb")
|> range(start: 2020-02-10T00:00:00Z, stop: 2020-02-11T00:00:00Z)
|> filter(fn: (r) => r._measurement == "netdata.users.cpu.influxdb")
|> filter(fn: (r) => r._field == "value")
|> filter(fn: (r) => r.host == "vpsfrsqlpac1")
|> aggregateWindow(every: 60s, fn: mean)
|> yield(name: "mean")influxdb% export INFLUX_ORG=sqlpac influxdb% influx query @$SCRIPTS/script1.fluxResult: mean Table: keys: [_start, _stop, _field, _measurement, host] _start:time _stop:time _field:string _measurement:string host:string _value:float _time:time ------------------------------ ------------------------------ ---------------------- -------------------------- ---------------------- ---------------------------- ------------------------------ 2020-02-10T00:00:00.000000000Z 2020-02-11T00:00:00.000000000Z value netdata.users.cpu.influxdb vpsfrsqlpac1 1.0997225 2020-02-10T00:43:00.000000000Z 2020-02-10T00:00:00.000000000Z 2020-02-11T00:00:00.000000000Z value netdata.users.cpu.influxdb vpsfrsqlpac1 0.7442834833333333 2020-02-10T17:44:00.000000000Z 2020-02-10T00:00:00.000000000Z 2020-02-11T00:00:00.000000000Z value netdata.users.cpu.influxdb vpsfrsqlpac1 0.9031700333333332 2020-02-10T00:45:00.000000000Z
L’option transpile
L’option transpile donne une traduction d’une requête InfluxQL en syntaxe Flux. Le résultat est fiable (pas complètement)
et utile quand on débute dans le langage Flux :
influxdb% influx transpile \ 'SELECT mean("value") AS "mean_value" FROM netdatatsdb.."netdata.users.cpu.influxdb" WHERE time >= now() -1h and time < now() and "host"='vpsfrsqlpac1' GROUP BY time(60s) FILL(null)'from(bucket: "netdatatsdb") |> range(start: 2020-02-10T12:59:32.850621715Z, stop: 2020-02-10T13:59:32.850621714Z) |> filter(fn: (r) => (r._measurement == "netdata.users.cpu.influxdb" and r._field == "value")) |> filter(fn: (r) => (r["host"] == r["vpsfrsqlpac1"])) |> group(columns: ["_measurement", "_start"], mode: "by") |> window(every: 1m) |> mean() |> duplicate(column: "_start", as: "_time") |> window(every: inf) |> map(fn: (r) => ({_time: r._time, mean_value: r._value}), mergeKey: true) |> yield(name: "0")
Mise à jour (9 mars 2021) : l’option transpile sera obsolète dans
les prochaines versions - GitHub Influxdata/Influxdb, fix(cmd/influx): delete unsupported influx transpile command
Outil de requête intégré
La meilleure option est d’utiliser l’outil de visualisation intégré, Chronograf n’est plus un outil à part. Cet outil
est très intuitif.
Ouvrir si nécessaire le port 9999 au niveau des règles firewall et créer les users avec les autorisations appropriées pour donner l’accès,
dans l’exemple ci-dessous le user netdata_ro est créé avec les autorisations "read buckets" et
"read/write dashboards" :
http://localhost:9999influxdb% influx user create --name netdata_ro --password "*******"
influxdb% influx auth create --user netdata_ro --org sqlpac --read-buckets --read-dashboards --write-dashboards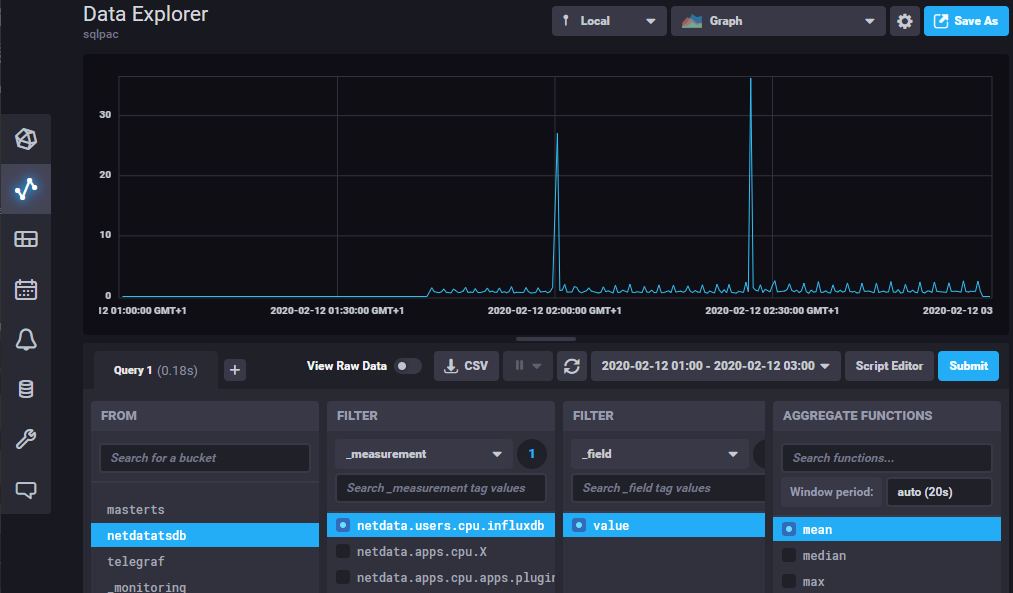
Écrire des séries
InfluxDB Line protocol
Pas de différence par rapport à InfluxDB v1.x, les points sont écrits avec le protocole InfluxDB Line Protocol. Utiliser influx write
pour écrire des points dans une série :
influxdb% export INFLUX_ORG=sqlpac
influxdb% export INFLUX_BUCKET_NAME=netdatatsdb
influxdb% influx write --precision s 'customMeasure,host=vpsfrsqlpac1 cpupct=23.4,slot=1i,isdefault=true 1581321757'- Le timestamp du serveur est utilisé si il est omis dans la ligne.
- Le type de données integer au lieu de float est forcé en ajoutant
iaprès la valeur lors de l’insertion du premier point. Le suffixeuest utilisé pour spécifier des entiers non signés (unsigned integers). - Le type de données Boolean est appliqué en écrivant
t|trueouf|falsesans quotes ou doubles quotes lors de l’insertion du premier point.
Appliquer le bon type de données renforce l’intégrité des données et réduit la consommation mémoire et d’espace.
Error: Failed to write data: unexpected error writing points to database: partial write: series type mismatch: already Integer but got Float dropped=1.Chargements en masse (Bulk loads)
Les lignes peuvent être importées à partir d’un fichier texte, cela fonctionne bien avec l’interface utilisateur (Load Data Buckets
Add data Line Protocol Upload File) mais les
lignes de commande lèvent des erreurs lorsque le fichier texte dépasse une taille de données (Bad Timestamp…).
Le produit est toujours en phase beta avec des améliorations à délivrer sur les imports en masse (fichier README),
aussi attendons les prochaines versions beta pour le moment. Bref, en tous cas la syntaxe est celle-ci :
influxdb% influx write --bucket netdatatsdb --precision s @data.txtSELECT INTO, fonction to()
Dans InfluxDB v1.7, les commandes SELECT INTO copient les données d’une mesure vers une autre.
Avec InfluxDB v2, utiliser la fonction to() :
from(bucket: "netdatatsdb")
|> range(start: -30d)
|> filter(fn: (r) => r._measurement == "netdata.users.cpu.influxdb")
|> filter(fn: (r) => r._field == "value")
|> filter(fn: (r) => r.host == "vpsfrsqlpac1")
|> to(bucket: "history", org: "sqlpac")Pour écrire dans le même bucket, la fonction set est appliquée pour modifier la clé _measurement :
from(bucket: "netdatatsdb")
|> range(start: -30d)
|> filter(fn: (r) => r._measurement == "netdata.users.cpu.influxdb")
|> filter(fn: (r) => r._field == "value")
|> filter(fn: (r) => r.host == "vpsfrsqlpac1")
|> set(key: "_measurement", value: "cpu_influxdb")
|> to(bucket: "netdatatsdb", org: "sqlpac")Informations Metadata
Où sont les commandes SHOW extrayant les informations sur les métadonnées ?
C’est la grande question lorsque l’on fait tourner pour la première fois un serveur InfluxDB v2 :
mais où sont donc passées les commandes favorites listant les informations sur les mesures, series, tag keys, tag values, field keys ? SHOW MEASUREMENTS, SHOW SERIES, SHOW TAG KEYS FROM,
SHOW TAG VALUES FROM, SHOW FIELD KEYS FROM.
Des fonctions d’aide sont disponibles mais elles n’ont pas toutes les capacités offertes par les commandes SHOW des versions 1.x.
Par ailleurs, certaines fonctions d’aide dépendent malheureusement de plages de temps (-30d) et deviennent imprécises lors
de la recherche de metadata anciennes.
Pour utiliser ces fonctions, le package influxdata/influxdb/v1 est importé. Pas facile lorsqu’on n’est pas encore habitué, mais voici certaines translations de base :
| InfluxQL | Flux |
|---|---|
|
|
|
|
|
|
La plage de temps peut devoir être ajustée. Par exemple, le code source de la fonction v1.measurementTagKeys
s’appuie sur la fonction tagKeys qui utilise l’intervalle -30d,
aussi lors de la recherche d’anciennes clés cet intervalle doit être personnalisé en conséquence :
|
|
Fondamentalement, par rapport à InfluxDB v1, l’outil de visualisation est maintenant souvent plus préférable avec InfluxDB v2 et Flux.
Continuous queries et Influx v2 : tasks
À propos des "Continuous Queries", par exemple cette requête continue avec un intervalle de 5 min :
CREATE CONTINUOUS QUERY cq_influxdb1_cpu ON netdatatsdb
BEGIN
SELECT mean(value) INTO netdatatsdb.autogen.avg_influxdb1_cpu
FROM netdatatsdb.autogen."netdata.users.cpu.influxdb"
WHERE host = 'vpsfrsqlpac1' GROUP BY time(5m)
ENDLes requêtes continues doivent être migrées en "task", avec une syntaxe un peu plus compliquée et une plage de temps obligatoire mais la possibilité d’insérer plus de logique ainsi que d’utiliser les nouveautés apportées par le langage Flux (jointures, data sources externes …), ce qui n’était pas possible dans la syntaxe InfluxQL des continuous queries :
task_influxdb1_cpu.flux
option task = {name: "task_influxdb1_cpu", every: 5m}
data = from(bucket: "netdatatsdb")
|> range(start: -duration(v: int(v: task.every) * 2))
|> filter(fn: (r) =>
(r._measurement == "netdata.users.cpu.influxdb"))
|> filter(fn: (r) =>
(r.host == "vpsfrsqlpac1"))
data
|> aggregateWindow(fn: mean, every: 5m)
|> to(bucket: "history", org: "sqlpac")La tâche est créée via l’interface graphique utilisateur ou en lignes de commandes avec influx task:
influxdb% export INFLUX_ORG=sqlpac
influxdb% influx task create @$SCRIPTS/@task_influxdb1_cpu.fluxLes logs des tasks sont disponibles en ligne de commandes :
influxdb% export INFLUX_ORG=sqlpac influxdb% influx task findID Name OrganizationID Organization AuthorizationID Status Every Cron 053db5267712f000 task_influxdb1_cpu e71686ff910f3f32 sqlpac <nil> active 5minfluxdb% influx task log find --task-id 053db5267712f000RunID Time Message 053db789b812f000 2020-02-14T18:25:00.017404174Z Started task from script: "option task = {name: \"task_influxdb1_cpu\", every: 5m}\n\ndata = from(bucket: \"netdatatsdb\")\n\t|> range(start: -duration(v: int(v: task.every) * 2))\n\t|> filter(fn: (r) =>\n\t\t(r._measurement == \"netdata.users.cpu.influxdb\"))\n\t|> filter(fn: (r) =>\n\t\t(r.host == \"vpsfrsqlpac1\"))\n\ndata\n\t|> aggregateWindow(fn: mean, every: 5m)\n\t|> to(bucket: \"history\", org: \"sqlpac\")" 053db789b812f000 2020-02-14T18:25:00.151736449Z Completed(success) 053db664c012f000 2020-02-14T18:20:00.015766176Z Started task from script: "option task = {name: \"task_influxdb1_cpu\", every: 5m}\n\ndata = from(bucket: \"netdatatsdb\")\n\t|> range(start: -duration(v: int(v: task.every) * 2))\n\t|> filter(fn: (r) =>\n\t\t(r._measurement == \"netdata.users.cpu.influxdb\"))\n\t|> filter(fn: (r) =>\n\t\t(r.host == \"vpsfrsqlpac1\"))\n\ndata\n\t|> aggregateWindow(fn: mean, every: 5m)\n\t|> to(bucket: \"history\", org: \"sqlpac\")" 053db664c012f000 2020-02-14T18:20:00.168045054Z Completed(success) 053db54aaf52f000 2020-02-14T18:15:11.176279364Z Started task from script: "option task = {name: \"task_influxdb1_cpu\", every: 5m}\n\ndata = from(bucket: \"netdatatsdb\")\n\t|> range(start: -duration(v: int(v: task.every) * 2))\n\t|> filter(fn: (r) =>\n\t\t(r._measurement == \"mem\"))\n\t|> filter(fn: (r) =>\n\t\t(r.host == \"vpsfrsqlpac1\"))\n\ndata\n\t|> aggregateWindow(fn: mean, every: 5m)\n\t|> to(bucket: \"history\", org: \"sqlpac\")" 053db54aaf52f000 2020-02-14T18:15:11.203447377Z Completed(success)
Configuration HTTPS/SSL
HTTPS/SSL nécessite des ajustements quand des certificats auto-signés (self-signed certificates) sont utilisés.
Même à des fins de développement, on peut souhaiter que les paquets HTTP soient encryptés, surtout sur le réseau internet, entre
le client et le serveur InfluxDB. Les clés publique et privée sont déjà préparées, mais pour rappel, utiliser openssl
pour rapidement créér des certificats auto-signés :
influxdb% openssl req -x509 -nodes -newkey rsa:2048 \
-keyout <directory>/srvifx2.key \
-out <directory>/srvifx2.crt \
-days 365Le certificat public (srvifx2.crt) est importé dans le magasin des certificats "Trusted Root Certification Authorities"
du client.
Ajouter les certificats privé et public dans la ligne de commande démarrant le serveur InfluxDB avec les options --tls-key et
--tls-cert.
influxdb% nohup influxd --bolt-path=/sqlpac/influxdb/${IFXSRVNAME}/srvifx2.bolt \
--engine-path=/sqlpac/influxdb/${IFXSRVNAME} \
--http-bind-address="vpsfrsqlpac2:9999" \
--tls-key=/var/ssl/VPSFRSQLPAC2.key \
--tls-cert=/var/ssl/VPSFRSQLPAC2.crt >> $LOG/srvifx2.log 2>&1 &Le protocole HTTPS est notifié dans le fichier de log du serveur :
ts=2020-02-12T12:20:03.115534Z lvl=info msg=Listening log_id=0Kvw4gil000 transport=https addr=vpsfrsqlpac2:9999 port=9999HTTPS est activé pour l’outil de visualisation : https://vpsfrsqlpac2:9999, mais maintenant l’outil client influx est rejeté :
influxdb% influx user findClient sent an HTTP request to an HTTPS server
La variable d’environnement INFLUX_HOST doit être mise à jour à https :
influxdb% export INFLUX_HOST=https://vpsfrsqlpac2:9999Mais ce n’est toujours pas suffisant lors de l’utilisation d’un certificate auto-signé :
influxdb% influx user findError: Get https://vpsfrsqlpac2:9999/api/v2/setup: x509: certificate signed by unknown authority.
L’option --skip-verify doit être ajoutée.
influxdb% influx --skip-verify user findUn alias peut être défini lors du sourcing d’un environnement InfluxDB, il évitera de répéter l’option --skip-verify.
influxdb% alias i="influx --skip-verify"Ce type de problème se produit aussi avec les plugins Telegraf :
2020-02-12T14:13:50Z E! [outputs.influxdb_v2] when writing to [http://vpsfrsqlpac2:9999]:
Post http://vpsfrsqlpac2:9999/api/v2/write?bucket=netdatatsdb&org=sqlpac: write tcp 10.xx.xxx.xxx:46314->10.xx.xxx.xxx:9999: write: broken pipe
2020-02-12T14:17:38Z E! [outputs.influxdb_v2] when writing to [https://vpsfrsqlpac2:9999]:
Post https://vpsfrsqlpac2:9999/api/v2/write?bucket=netdatatsdb&org=sqlpac: x509: certificate signed by unknown authorityMettre à jour en conséquence la configuration de l’agent Telegraf pour indiquer https
ainsi que l’option insecure_skip_verify à true:
tgfagent_netdata.conf
[[outputs.influxdb_v2]]
urls = ["https://vpsfrsqlpac2:9999"]
insecure_skip_verify = true
Telegraf - Parallel runs
Les supports natifs des protocoles OpenTSDB, Graphite, Prometheus, CollectD, UDP sont supprimés dans la version 2.
Un agent Telegraf doit être configuré entre l’application et le serveur InfluxDB v2 pour gérer ces architectures.
Use case
Voici un cas d’utilisation : Netdata envoie ses métriques à travers le protocole OpenTSDB vers un serveur InfluxDB version 1.7 / port 4242
netdata.conf
[backend]
# host tags =
enabled = yes
data source = average
type = opentsdb
destination = tcp:vpsfrsqlpac2:4242
prefix = netdata
hostname = vpsfrsqlpac1
update every = 10
buffer on failures = 10
timeout ms = 20000
Les métriques sont envoyés avec la syntaxe OpenTSDB suivante :
put netdata.users.sockets.daemon 1579463790 0.0000000 host=vpsfrsqlpac1Malheureusement, Telegraf ne dispose pas de plugin OpenTSDB en Input, seulement en output, mauvaise nouvelle…
Mais Netdata peut envoyer également ses métriques avec le protocole graphite et Telegraf supporte le format de données Graphite
avec le plugin socket_listener en input.
L’architecture cible sera donc la suivante :
- Netdata envoie ses métriques dans le format graphite à l’agent Telegraf sur le port 14001.
- Telegraf pousse les métriques vers les 2 serveurs InfluxDB v1.7 et InfluxDB v2, autant mettre en place un parallel run puisque techniquement c’est possible.
Les versions 1.9 et supérieures de Telegraf sont requises pour InfluxDB v2.
Installation et configuration
Télécharger et installer Telegraf
influxdb% cd /opt/influxdata
influxdb% wget https://dl.influxdata.com/telegraf/releases/telegraf-1.13.3_linux_amd64.tar.gz
influxdb% tar xzvf telegraf-1.13.3_linux_amd64.tar.gz
influxdb% export PATH=/opt/influxdata/telegraf/usr/bin:$PATH
influxdb% export TGF_CFG=/opt/influxdata/dba/telegraf/cfg
influxdb% export TGF_LOG=/opt/influxdata/dba/telegraf/logLe fichier de configuration de l’agent Telegraf (tgf_netdata.conf) sera installé
dans le répertoire $TGF_CFG défini ci-dessus.
Pour générer le fichier de configuration :
- Input plugin :
socket_listener - Output plugins : InfluxDB v1 et InfluxDB v2
influxdb:influxdb_v2
telegraf --input-filter socket_listener --output-filter influxdb:influxdb_v2 config > $TGF_CFG/tgf_netdata.confDans la configuration générale, le paramètre omit_hostname est défini à true, sinon
le tag host est automatiquement ajouté par l’agent telegraf et il écrase le tag host envoyé par NetData.
[agent]
omit_hostname = trueLe plugin input est configuré : port 14001 et format de données graphite.
[[inputs.socket_listener]]
service_address = "tcp://:14001"
data_format = "graphite"
templates = [
"measurement.host.measurement*"
]Un modèle est appliqué. En effet lorsque NetData envoie ses données dans le format graphite, le format est le suivant :
netdata.vpsfrsqlpac1.users.cpu.postgres 0.0000000 1579463970Mais on veut que le nom du host soit une clé de balise ou tag key (host=vpsfrsqlpac1)
et qu’il ne soit pas défini dans le nom de la mesure :
netdata.users.cpu.postgres,host=vpsfrsqlpac1 0.0000000 1579463970Le modèle ci-dessous effectue cette transformation :
// Transform netdata.host.endofmeasurename value timestamp => netdata.endofmeasurement,host=xxxxx value timestamp
templates = [
"measurement.host.measurement*"
]Dans la configuration output vers le serveur InfluxDB 1.7, dans ce use case, https n’est pas implémenté
et le compte influxdb se connecte au serveur, aucun identifiant de connexion n’est requis.
[[outputs.influxdb]]
urls = ["http://vpsfrsqlpac1:8086"]
database = "netdatatsdb"
skip_database_creation = trueDans la configuration output vers le serveur InfluxDB 2, https est implémenté aussi l’option
insecure_skip_verify est définie à true. L’adresse URL, le token, l’organisation et le bucket sont spécifiés.
[[outputs.influxdb_v2]]
urls = ["https://vpsfrsqlpac2:9999"]
token = "8onYTPhtWbn7F4543PkgtBRIQE62YBK9o9QRqIm3n8SawmQ_l8yXTWwwdfkeZ-K-Rso1Ab1H_nrlhaXt9ZRDeg=="
organization = "sqlpac"
bucket = "netdatatsdb"
insecure_skip_verify = trueLe token est le token généré pour le user telegraf, user créé dans le serveur InfluxDB v2 avec les droits
read/write sur les buckets de l’organisation :
influxdb% export INFLUX_HOST=https://vpsfrsqlpac2:9999
influxdb% export INFLUX_ORG=sqlpac
influxdb% alias i="influx --skip-verify"
influxdb% i user create --name telegraf --password "***************"
influxdb% i auth create --user telegraf --read-buckets --write-bucketsLancement de Telegraf
La configuration Netdata est donc définie au format de données graphite vers le port 14001 de l’agent Telegraf et NetData est redémarré :
[backend]
enabled = yes
data source = average
type = graphite
destination = tcp:vpsfrsqlpac2:14001
prefix = netdata
hostname=vpsfrsqlpac1
update every = 10
buffer on failures = 10
timeout ms = 20000Pour lancer l’agent Telegraf (en mode debug ci-dessous pour vérifier que la configuration est la bonne) :
influxdb% nohup telegraf --config $TGF_CFG/tgf_netdata.conf \
--debug >> $TGF_LOG/tgf_netdata.log 2>&1 &Quand les flux en sortie sont correctement définis :
2020-02-14T17:44:17Z I! Starting Telegraf 1.13.3
2020-02-14T17:44:17Z I! Loaded inputs: socket_listener
2020-02-14T17:44:17Z I! Loaded aggregators:
2020-02-14T17:44:17Z I! Loaded processors:
2020-02-14T17:44:17Z I! Loaded outputs: influxdb influxdb_v2
2020-02-14T17:44:17Z I! Tags enabled:
2020-02-14T17:44:17Z I! [agent] Config: Interval:10s, Quiet:false, Hostname:"", Flush Interval:10s
2020-02-14T17:44:17Z D! [agent] Initializing plugins
2020-02-14T17:44:17Z D! [agent] Connecting outputs
2020-02-14T17:44:17Z D! [agent] Attempting connection to [outputs.influxdb]
2020-02-14T17:44:17Z D! [agent] Successfully connected to outputs.influxdb
2020-02-14T17:44:17Z D! [agent] Attempting connection to [outputs.influxdb_v2]
2020-02-14T17:44:17Z D! [agent] Successfully connected to outputs.influxdb_v2
2020-02-14T17:44:17Z D! [agent] Starting service inputs
2020-02-14T17:44:17Z I! [inputs.socket_listener] Listening on tcp://[::]:14001
2020-02-14T17:44:20Z D! [outputs.influxdb_v2] Wrote batch of 1000 metrics in 44.85221ms
2020-02-14T17:44:20Z D! [outputs.influxdb_v2] Buffer fullness: 1979 / 10000 metrics
2020-02-14T17:44:20Z D! [outputs.influxdb] Wrote batch of 1000 metrics in 57.396782ms
2020-02-14T17:44:20Z D! [outputs.influxdb] Buffer fullness: 1979 / 10000 metricsUn parallel run est à présent en place, il ne reste plus qu’à définir l’agent Telegraf en tant que service.
InfluxDB v2 et le reporting avec Grafana
Un plugin pour Flux (InfluxDB Flux Datasource), encore en version beta, est disponible. Il nécessite Grafana 6.5 et versions supérieures. Pour l’installer :
grafana% grafana-cli --pluginsDir ~/grafana-6.6.1/data/plugins plugins install grafana-influxdb-flux-datasourceRedémarrer le serveur Grafana.
Créer un user grafana dans le serveur InfluxDB avec les droits appropriés, au moins en lecture seule sur le(s) bucket(s) :
influxdb% export INFLUX_HOST=https://vpsfrsqlpac2:9999
influxdb% export INFLUX_ORG=sqlpac
influxdb% alias i="influx --skip-verify"
influxdb% i user create --name grafana --password "***************"
influxdb% i auth create --user grafana --read-buckets
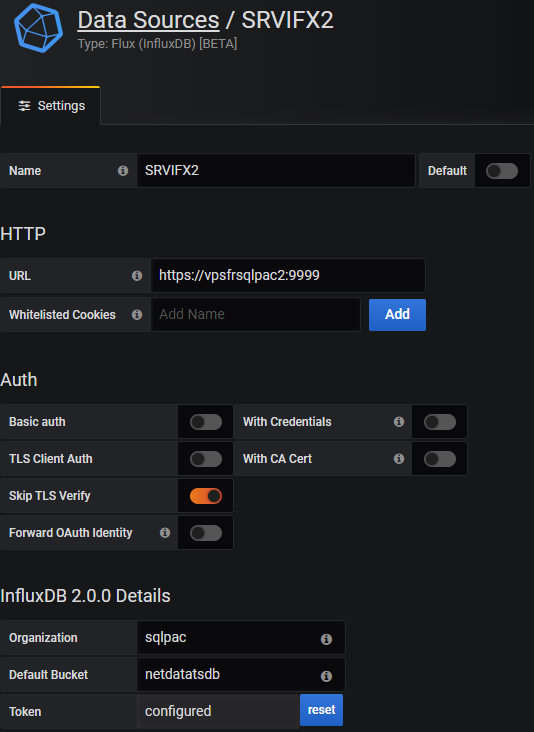
Dans Grafana, créer une source de données avec le plugin "Flux (InfluxDB) [BETA]"
- Définir l’option "Skip TLS verify" à "
on" lorsque HTTPS/SSL est utilisé. - Renseigner l’organisation et le bucket par défaut.
- Renseigner le champ "Token" avec le token créé lors de la définition de l’authentification plus haut.
Ça fonctionne, mais un peu décevant pour le moment, il faut attendre, le plugin est toujours en phase beta et l’explorateur graphique (UI explorer) n’est pas encore implémenté afin d’éviter d’écrire la syntaxe Flux.
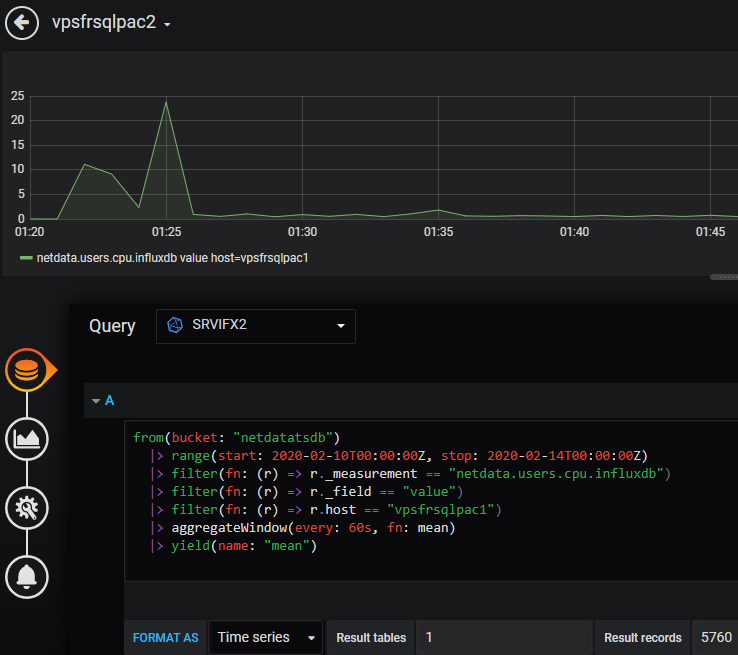
Quand l’explorateur UI sera livré, tout devrait être fonctionnel sans avoir à écrire la syntaxe Flux comme c’est le cas avec le plugin pour InfluxQL / InfluxDB v1. La migration des tableaux de bord existants InfluxDB v1.x InfluxQL va sûrement impliquer des exports/imports au format JSON (sources de données, traduction des requêtes d’InfluxQL vers Flux …).
Conclusion
Il y a de nombreuses nouvelles fonctionnalités intéressantes avec InfluxDB v2: jointures, pivot, sources de données externes dans le langage Flux, mais un travail non négligeable est à prévoir pour la migration :
- des "Continuous queries" en "Tasks Flux".
- des alimentations existantes utilisant les protocoles OpenTDS/Graphite… vers Telegraf.
- des tableaux de bords Grafana vers le langage Flux.
C’est le problème d’une nouvelle version majeure comprenant un refactoring : ruptures nécessitant une réécriture de code, fonctionnalités qui deviennent obsolètes… Des raisons pour lesquelles d’autres produits sont alors parfois étudiés. La rupture générée avec le langage Flux est importante, mais après avoir franchi la barrière de l’apprentissage du langage Flux, ce langage offre des fonctionnalités procédurales très intéressantes et lève toutes les limitations que le langage InfluxQL comportaient.