
Introduction
Lors de l’installation de NetData, un puissant outil de monitoring, une question se pose rapidement: où conserver et stocker les mesures ?
NetData offre la possibilité de stocker les mesures dans une base de données InfluxDB, une base de données dite "Time Series", à travers le protocole OpenTSDB (Open TimeSeries Database protocol).
InfluxDB est une base performante avec une compression efficace, entièrement écrite en Go elle est sans dépendances externes. InfluxDB peut être facilement interfacée avec Grafana à des fins de reporting. InfluxQL est le langage de requête pour travailler sur les données d’une base InfluxDB et à partir de la version 1.7, le langage Flux est introduit et peut être activé : Flux sera le langage de la prochaine version majeure d’InfluxDB, mais malheureusement ce dernier s’éloigne énormément du langage SQL.
Voyons l’architecture d’InfluxDB et comment l’utiliser.
Architecture
Terminologie : mesures, séries, clés (keys), valeurs
Les bases de données stockent des mesures (measurements). Dans l’exemple ci-dessous, 2 mesures : netdata.users.mem.root and
netdata.users.cpu.root.
- Si la mesure n’existe pas lors de l’insertion, la mesure est créée.
- Le temps est en Epoch time (nanoseconds) :
1580940454000000000↔02/05/2020 @ 10:07pm (UTC). De nombreux outils de conversion existent, en dehors des langages de programmation.
- Des clés de balises (tag keys) peuvent être définies dans une ligne. Dans l’exemple ci-dessus, 1 clé de balise :
host - Une ou plusieurs clés de champs (field keys) sont définies dans une ligne. Dans l’exemple, 1 clé de champ :
value - Les séries sont les combinaisons possibles mesure/tag keys:
Dans la mesure ci-dessusmeasurement, tag key1=value1, tag key2=value2 [,...]netdata.users.cpu.root, 2 séries :netdata.users.cpu.root,host=vpsfrsqlpac1 netdata.users.cpu.root,host=vpsfrsqlpac2
Le protocole ligne InfluxDB
Le protocole ligne InfluxDB est un format texte pour écrire des points dans InfluxDB. Son format est très simple :
Avec le client influx, créons des points dans la base netdatatsdb :
influxdb% influx -database 'netdatatsdb'> insert cpu_measurement,location=france,host=vpsfrsqlpac1 value=25.089878,description="low usage" 1580918550000000000 > insert cpu_measurement,location=germany,host=vpsfrsqlpac2 value=75.089878,description="high usage" 1580918550000000000 > select * from cpu_measurement;time description host location value ---- ----------- ---- -------- ----- 1580918550000000000 high usage vpsfrsqlpac2 germany 75.089878 1580918550000000000 low usage vpsfrsqlpac1 france 25.089878
Lorsque le timestamp est omis, InfluxDB utilise le timestamp UTC du serveur en nanosecondes.
Balises ou champs (Tags or fields) ? Recommandations générales
Les balises sont indexées et les champs ne le sont pas. Les requêtes doivent guider ce qui est stocké sous forme de balise et ce qui est stocké sous forme de champ.
- Stocker les données dans les balises (tags) quand il s’agit de méta-données ou si il est prévu d’utiliser celles-ci dans des clauses
GROUP BY. - Important : les valeurs des balises sont toujours interprétées comme des chaînes de caractères, donc les champs doivent être utilisés si on a besoin de traiter la donnée autrement qu’en chaîne de caractères.
- Stocker la donnée dans des champs si elle est utilisée dans des fonctions SQL (
SUM,COUNT…). - Ne pas utiliser le même nom pour une balise et un champ.
- Autant que possible, ne pas encoder de données dans les noms de mesures et les valeurs de balises afin d’éviter les expressions régulières.
Par exemple, utiliser
plot=1,region=northau lieu delocation=plot-1.northpour éviter l’expression régulière suivante dans les requêtes :SELECT … FROM <measurement> WHERE location =~ /\.north$/
Bases de données, politiques de rétention (retention policies) et fragments (shards)
Une politique de rétention est définie dans une base de données, celle-ci peut être infinie et c’est
la politique de rétention par défaut (autogen). InfluxDB
stocke les données dans des groupes de fragments (shard groups). Les groupes de fragments sont gouvernés
par la politique de rétention et stockent les données par intervalles de temps appelés
durée de fragment (shard duration).
Les durées des groupes de fragments peuvent être définies par l’utilisateur, sinon les valeurs par défaut ci-dessous sont appliquées :
| Durée de la politique de rétention (Retention policy duration) | Durée d’un fragment (Shard group duration) |
< 2 jours
>= 2 jours and <= 6 mois
> 6 mois |
1 heure
1 jour
7 jours |
Les durées des groupes de fragments par défaut sont bien adaptées dans la plupart des cas. Toutefois, les instances à haut débit ou de longue durée bénéficient de durées de fragments plus longues. Recommandations :
| Durée de la politique de rétention (Retention policy duration) | Durée d’un fragment (Shard group duration) |
<= 1 jour
> 1 jour and <= 7 jours
> 7 jours and <= 3 mois
> 3 mois
infini |
6 heures
1 jour
7 jours
30 jours
52 semaines ou plus |
In Memory indexing et Time-Structured Merge Tree (TSM)
Dans la version 1.7, le moteur de stockage par défaut est le moteur "In Memory Index". Un nouveau moteur de stockage est disponible (TSI : Time Series Index) mais il n’est pas activé par défaut, ce moteur de stockage est abordé dans le prochain paragraphe.
Chaque base de données a ses propres fichiers WAL (Write Ahead Log) et TSM.
- Les segments WAL stockent les blocs compressés des écritures et suppressions.
- Les fichiers TSM stockent les données compressées des séries en colonnes (columnar format).
- Le cache est une représentation en mémoire (in-memory) des données stockées dans le WAL. Il est interrogé à l’exécution et fusionné avec les données stockées dans les fichiers TSM.
- L’index In-Memory est un index partagé par les fragments qui fournit un accès rapide aux mesures, balises et séries.
Time Series Index (TSI)
À partir de la version 1.3, le moteur TSI est apparu. Il est encore désactivé par défaut car une migration est en effet nécessaire pour les bases existantes.
Le moteur In memory - TSM montrait des limitations pour les systèmes utilisant des millions de séries avec une haute cardinalité : jusqu’au moteur TSI, l’index était une structure en mémoire construit au démarrage de la base à partir des données dans les TSM. L’utilisation de la mémoire ne cessait d’augmenter au fur et à mesure que des séries étaient créées.
Le nouvel index TSI (Time Series Index) est stocké dans des fichiers sur disque, fichiers mappés avec la mémoire. Dans ce contexte, c’est le système d’exploitation qui gère la mémoire LRU (Least Recently Used). Des routines en arrière plan compactent en continu l’index dans des fichiers de plus en plus grands afin d’éviter la fusion de trop nombreux petits indexes lors d’une requête.
Protocoles supportés
Pour ce qui concerne l’ingestion de données, InfluxDB supporte les protocoles ci-dessous et de multiples listeners peuvent être définis :
- Collectd
- Graphite
- OpenTSDB
- Prometheus
- UDP
À partir de la version 2 d’InfluxDB, actuellement en phase beta (Février 2020), ces protocoles ne seront plus nativement supportés : telegraf devra être utilisé.
Installation
Un package debian est disponible pour Ubuntu mais dans cet article, comme il s’agit d’une installation "non-root", ce sont les binaires Linux 64 bits version 1.7.9 qui sont téléchargés du site Web InfluxDB.
L’installation est réalisée avec l’utilisateur influxdb dans le répertoire /opt/influxdb.
influxdb% cd /opt/influxdb
influxdb% wget https://dl.influxdata.com/influxdb/releases/influxdb-1.7.9_linux_amd64.tar.gz
influxdb% tar xvfz influxdb-1.7.9_linux_amd64.tar.gzLa structure de la distribution est alors la suivante :
/opt/influxdb/influxdb-1.7.9-1
|___etc
|___usr
|___varUn lien symbolique influxdb-1.7 est créé pour plus de facilité et la gestion des upgrades.
influxdb% ln -fs influxdb-1.7.9-1 influxdb-1.7La variable d’environnement $IFXHOME pointe sur le répertoire racine de la distribution
et la variable $IFXBIN sur le répertoire où les binaires client et serveur (influxd, influx, …)
sont installés.
Le répertoire $IFXBIN est ajouté à la variable d’environnement $PATH.
influxdb% export IFXHOME=/opt/influxdb/influxdb-1.7
influxdb% export IFXBIN=$IFXHOME/usr/bin
influxdb% export PATH=$IFXBIN:$PATH3 variables d’environnement personnalisées, $CFG, $LOG et $RUN, sont créées
pour les répertoires des fichiers de configuration, de log, et du process ID :
influxdb% export CFG=/opt/influxdb/dba/srvifxsqlpac/cfg
influxdb% export LOG=/opt/influxdb/dba/srvifxsqlpac/log
influxdb% export RUN=/opt/influxdb/dba/srvifxsqlpac/runC’est fini, pas besoin de définir d’autres variables pour les librairies, etc.
Préparation du fichier de configuration
Un fichier de configuration modèle influxdb.conf est disponible dans le répertoire $IFXHOME/etc
Créer le fichier de configuration à partir de ce fichier modèle et personnaliser les directives pour la localisation de la base de données (meta, data, wal) :
$CFG/srvifxsqlpac.conf
[meta]
dir = "/sqlpac/influxdb/srvifxsqlpac/meta"
[data]
dir = "/sqlpac/influxdb/srvifxsqlpac/data"
wal-dir = "/sqlpac/influxdb/srvifxsqlpac/wal"Si il est prévu de commencer à utiliser le langage Flux, language qui offre de nombreuses nouvelles fonctionnalités (jointures, pivot, accès à des sources de données externes…), celui-ci doit être activé dans le fichier de configuration :
[http]
flux-enabled = trueLe port par défaut est le port 8086. Il peut être modifié dans le fichier de configuration :
[http]
bind-address = ":8086"Démarrage du serveur
Pour démarrer le serveur InfluxDB, lancer influxd avec l’option -config donnant le chemin
du fichier de configuration :
nohup $IFXBIN/influxd -pidfile /tmp/srvifxsqlpac.pid -config $CFG/srvifxsqlpac.conf >> $LOG/srvifxsqlpac.log 2>&1 &L’option -pidfile est utilisée pour gérer plus facilement la procédure d’arrêt.
Connexion au serveur
Pour se connecter et exécuter des commandes InfluxQL, lancer le client influx :
influxdb% influxConnected to http://localhost:8086 version 1.7.9 InfluxDB shell version: 1.7.9> SHOW DATABASES;name: databases name ---- _internal
Arrêt du serveur
Pour arrêter le serveur :
influxdb% kill -s TERM <processid influxd> influxdb% PIDFILE=$(cat $RUN/srvifxsqlpac.pid)
influxdb% kill -s TERM $PIDFILEGestion des bases de données, politiques de rétention et fragments (shards)
Création d’une base de données
Facile : exécuter CREATE DATABASE
influxdb% influx> CREATE DATABASE netdatatsdb;
Si le paramètre retention-autocreate n’est pas à false dans le fichier de configuration,
la politique de rétention par défaut autogen (durée infinie) est activée dans la base de données :
USE netdatatsdb; SHOW RETENTION POLICIES;name duration shardGroupDuration replicaN default ---- -------- ------------------ -------- ------- autogen 0s 168h0m0s 1 true
La réplication est à 1. La réplication n’est disponible que dans la version Enterprise.
Comme la rétention est infinie, la durée de fragment appliquée par défaut est de 7 jours (168 hours). La commande SHOW SHARDS
donne plus de détails sur les fragments existants :
SHOW SHARDS;id database retention_policy shard_group start_time end_time expiry_time owners -- -------- ---------------- ----------- ---------- -------- ----------- ------ 15 netdatatsdb autogen 15 2019-12-23T00:00:00Z 2019-12-30T00:00:00Z 2019-12-30T00:00:00Z 22 netdatatsdb autogen 22 2020-01-06T00:00:00Z 2020-01-13T00:00:00Z 2020-01-13T00:00:00Z 26 netdatatsdb autogen 26 2020-01-13T00:00:00Z 2020-01-20T00:00:00Z 2020-01-20T00:00:00Z 47 netdatatsdb autogen 47 2020-01-20T00:00:00Z 2020-01-27T00:00:00Z 2020-01-27T00:00:00Z 58 netdatatsdb autogen 58 2020-02-03T00:00:00Z 2020-02-10T00:00:00Z 2020-02-10T00:00:00Z
Politiques de rétentions et fragments
Une politique de rétention autogen est créée et prédéfinie, évidemment elle peut être modidiée en créant ou en altérant des
politiques de rétention.
CREATE RETENTION POLICY retention_infinite ON telegraf
DURATION inf REPLICATION 1 SHARD DURATION 52w DEFAULT;USE telegraf; SHOW RETENTION POLICIES;name duration shardGroupDuration replicaN default ---- -------- ------------------ -------- ------- autogen 0s 168h0m0s 1 false retention_infinite 0s 8736h0m0s 1 true
La clause REPLICATION est obligatoire dans la commande CREATE même si l’édition Community OSS est utilisée.
ALTER RETENTION POLICY autogen ON netdatatsdb SHARD DURATION 52w; ALTER RETENTION POLICY autogen ON netdatatsdb DEFAULT; USE netdatatsdb; SHOW RETENTION POLICIES;name duration shardGroupDuration replicaN default ---- -------- ------------------ -------- ------- autogen 0s 8736h0m0s 1 true
À propos des fragments, le moteur s’occupe de leur pré-création. Leur pré-création peut toutefois être contrôlée dans le fichier de configuration.
[shard-precreation]
# Determines whether shard pre-creation service is enabled.
enabled = true
# The interval of time when the check to pre-create new shards runs.
check-interval = "10m"
# The default period ahead of the endtime of a shard group that its successor group is created.
advance-period = "30m"
Interroger et écrire des données
Informations sur les métadonnées : mesures, séries, clés de balises et de champs
La commande SHOW affiche les informations utiles sur les métadonnées : mesures, séries, clés de balises et de champs…
Utiliser SHOW MEASUREMENTS pour lister les mesures, les expressions régulières peuvent y être utilisées :
SHOW MEASUREMENTS;… netdata.users.vmem.alerta netdata.users.vmem.apache netdata.users.vmem.daemon …
SHOW MEASUREMENTS WITH MEASUREMENT =~ /dbengines/;… netdata.dbengines.cpu.influxd netdata.dbengines.cpu.mysqld netdata.dbengines.cpu.postgres …
Pour lister les séries, SHOW SERIES :
SHOW SERIES;… netdata.users.vmem.mcs,host=vpsfrsqlpac1 netdata.users.vmem.mcs,host=vpsfrsqlpac2 netdata.users.vmem.messagebus,host=vpsfrsqlpac1 netdata.users.vmem.messagebus,host=vpsfrsqlpac2 netdata.users.vmem.mongodb,host=vpsfrsqlpac1 …
SHOW SERIES FROM "netdata.users.cpu.postgres";key --- netdata.users.cpu.postgres,host=vpsfrsqlpac1 netdata.users.cpu.postgres,host=vpsfrsqlpac2
SHOW SERIES FROM "netdata.users.cpu.postgres" WHERE host = 'vpsfrsqlpac1';key --- netdata.users.cpu.postgres,host=vpsfrsqlpac1
SHOW SERIES FROM "netdata.users.cpu.postgres" WHERE host !~ /vpsfrsqlpac1/;key --- netdata.users.cpu.postgres,host=vpsfrsqlpac2
Les clés de balises et de champs (Tag/field keys) sont également listées avec des commandes SHOW,
y compris la possibilité de lister les valeurs distinctes des clés de balises dans une mesure :
SHOW TAG KEYS FROM "cpu_measurement";name: cpu_measurement tagKey ------ host location
SHOW TAG VALUES FROM "cpu_measurement" WITH KEY=location;name: cpu_measurement key value --- ----- location france location germany
SHOW FIELD KEYS FROM "cpu_measurement";name: cpu_measurement fieldKey fieldType -------- --------- description string value float
Requêtes
Spécifier la précision rfc3339 pour convertir automatiquement les timestamps Unix en temps lisible.
PRECISION rfc3339SELECT MEAN(value) AS mean_value FROM "netdata.users.cpu.postgres" WHERE time > '2020-01-16T02:30:00.000Z' AND time < '2020-01-16T03:30:00.000Z' AND host = 'vpsfrsqlpac1' GROUP BY time(10s)name: netdata.users.cpu.postgres time mean_value ---- ---------- 2020-01-16T02:41:10Z 1.68414 2020-01-16T02:41:20Z 1.19909 2020-01-16T02:41:30Z 1.17531
Les sous-requêtes sont autorisées.
De très nombreuses fonctions InfluxQL sont à disposition.
Écrire des données
Renforcer les types de données
Écrivons un point :
INSERT cpu_measurement,location=france,host=vpsfrsqlpac1 cpupct=32.887384,slot=1 SELECT * FROM cpu_measurementname: cpu_measurement time cpupct host location slot ---- ------ ---- -------- ---- 1581037980496337504 32.887384 vpsfrsqlpac1 france 1
Le type de la colonne est automatiquement défini à l’insertion du premier point :
SHOW FIELD KEYS FROM cpu_measurementname: cpu_measurement fieldKey fieldType -------- --------- cpupct float slot float
Le type de données pour la colonne slot a été automatiquement défini à float.
Pour définir un type de données précis : integer pour la colonne slot,
ajouter i après la valeur lors de l’insertion du premier point. Pour le type de données boolean,
s’assurer d’écrire true ou false sans quotes ou double quotes:
INSERT cpu_measurement,location=france,host=vpsfrsqlpac1 cpupct=32.887384,slot=1i,active=true SHOW FIELD KEYS FROM cpu_measurementname: cpu_measurement fieldKey fieldType -------- --------- active boolean cpupct float slot integer
Appliquer le bon type de données réduit les consommations de mémoire et d’espace et cela renforce l’intégrité des données : les lignes avec de mauvaises valeurs seront rejetées.
INSERT cpu_measurement,location=france,host=vpsfrsqlpac1 cpupct=32.887384,slot=1.121212ERR: {"error":"partial write: field type conflict: input field \"slot\" on measurement \"cpu_measurement\" is type float, already exists as type integer dropped=1"}
Import en masse (Bulk import)
L’import en masse est très facile, il faut juste créér un fichier avec une en-tête contenant des clauses DDL/DML CONTEXT-DATABASE
puis les lignes au protocole Ligne InfluxDB :
prices.txt
# DDL
CREATE DATABASE finance
# DML
# CONTEXT-DATABASE: finance
prices,type=NSDQ open=10.62,high=10.82,low=10.62,clot=10.65,capit=3.09 1580918400
prices,type=NSDQ open=10.65,high=10.95,low=10.64,clot=10.59,capit=3.09 1581004800La base de données peut déjà exister, sinon elle est créée. La clause DML indique quelle base de données utiliser.
Le client influx est exécuté pour importer :
influxdb% influx -import -path=prices.txt -precision=s2020/02/07 13:12:53 Processed 1 commands 2020/02/07 13:12:53 Processed 1249 inserts 2020/02/07 13:12:53 Failed 0 inserts
influxdb% influx -database finance -precision rfc3339select * from prices limit 2name: prices time capit clot high low open type ---- ----- ---- ---- --- ---- ---- 2020-02-05T16:00:00Z 3.09 10.65 10.82 10.62 10.62 NSDQ 2020-02-06T16:00:00Z 3.09 10.59 10.95 10.64 10.65 NSDQ
SELECT INTO
Les données et résultats de requêtes peuvent être copiés, y compris dans un contexte de bases de données croisées (cross databases),
avec la commande SELECT INTO.
USE finance; SELECT * INTO mydb..prices from prices;name: result time written ---- ------- 0 2
Les requêtes continues (Continuous queries) peuvent automatiser les commandes SELECT INTO afin de
calculer/aggréger des résultats… mais cette fonctionnalité n’est pas couverte ici dans cette introduction, c’est un chapître
à part, il y a beaucoup de choses à dire sur ce sujet.
Listeners et ingestion des données
InfluxDB 1.x supporte nativement les protocoles ci-dessous pour l’ingestion de données :
- Graphite
- OpenTDS
- CollectD
- Prometheus
- UDP
Avec InfluxDB V2, ce ne sera plus possible, telegraf sera obligatoire pour alimenter une base InfluxDB à travers ces protocoles.
Juste un exemple ici : Netdata envoie ses métriques avec le protocole OpenTDS, aussi un listener OpenTDS (port 4242) est défini dans le fichier de configuration du serveur InfluxDB. Une base de données est attachée au listener, elle sera créée si elle n’existe pas. De multiples listeners peuvent être définis.
$CFG/srvifxsqlpac.conf
[[opentsdb]]
enabled = true
bind-address = ":4242"
database = "netdatatsdb"Le port OpenTDS du serveur InfluxDB est spécifié dans le fichier de configuration de Netdata :
netdata.conf
[backend]
# host tags =
enabled = yes
data source = average
type = opentsdb
destination = tcp:vpsfrsqlpac1:4242
prefix = netdata
update every = 10
buffer on failures = 10
timeout ms = 20000Visualisation des données
Chronograf
Un outil de visualisation est disponible en téléchargement : Chronograf. L’installation est très facile.
influxdb% cd /opt/influxdb
influxdb% wget https://dl.influxdata.com/chronograf/releases/chronograf-1.7.16_linux_arm64.tar.gz
influxdb% tar xvfz chronograf-1.7.16_linux_arm64.tar.gz
influxdb% ln -fs chronograf-1.7.16-1 chronograf-1.7Pour démarrer Chronograf sur le port 8087 :
influxdb% cd /opt/influxdb influxdb% nohup ./chronograf-1.7/usr/bin/chronograf --port 8087 \ --influxdb-url=http://vpsfrsqlpac1:8086 \ --bolt-path $CFG/chronograf/chronograf.db >> /dev/null 2>> $LOG/chronograf.log &time="2020-02-06T15:06:51+01:00" level=info msg="Serving chronograf at http://[::]:8087" component=server
La base de données bolt (--bolt-path), créée au premier lancement de Chronograf, stocke la définition des tableaux de bord…
L’outil est très simple et intuitif.
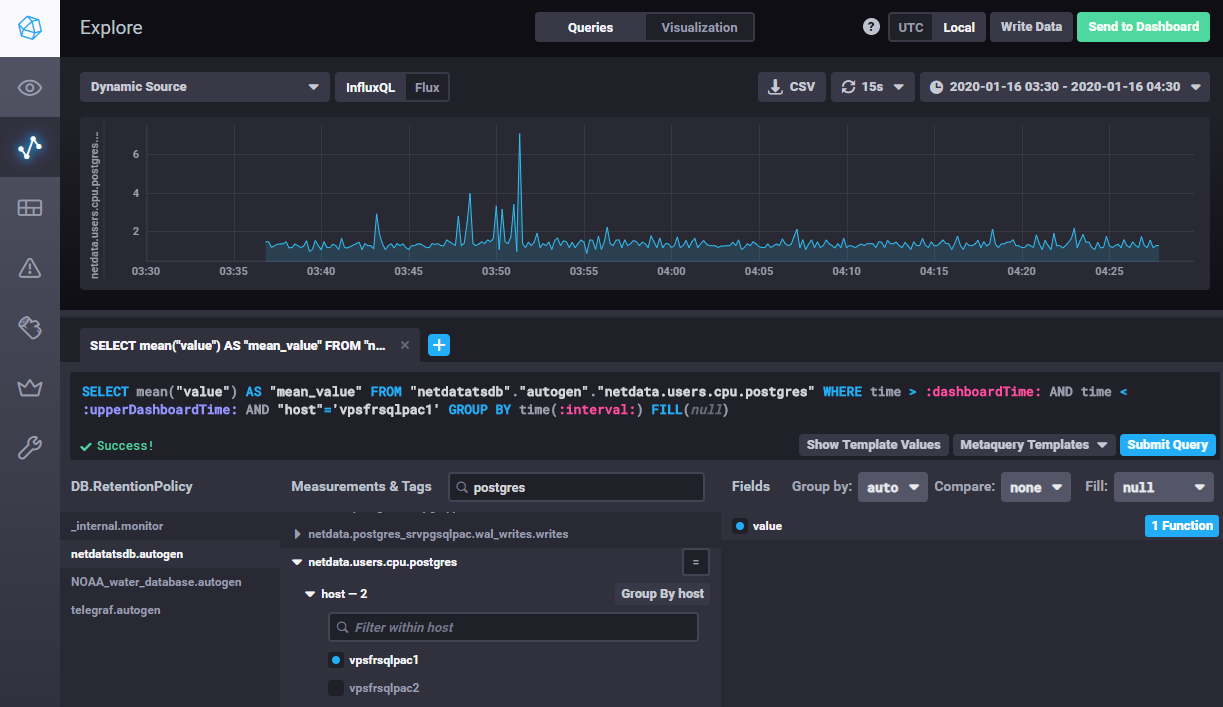
À partir d’InfluxDB version 1.7.x et si le langage Flux est activé dans le fichier de configuration
(flux-enabled = true), les 2 langages InfluxQL et Flux sont proposés dans Chronograf : des boutons dans le menu autorisent
la bascule de l’un à l’autre. Cette fonctionnalité sera utile pour préparer la migration vers InfluxDB v2, InfluxQL sera en effet supprimé
dans cette version et Flux sera l’unique langage.

Information supplémentaire : à partir de la version 2.0, les fonctionnalités de Chronograf seront intégralement incorporées dans InfluxDB, ce ne sera plus un outil à part et autonome.
Grafana
Grafana intègre facilement des tableaux de bords avec InfluxDB en source de données.
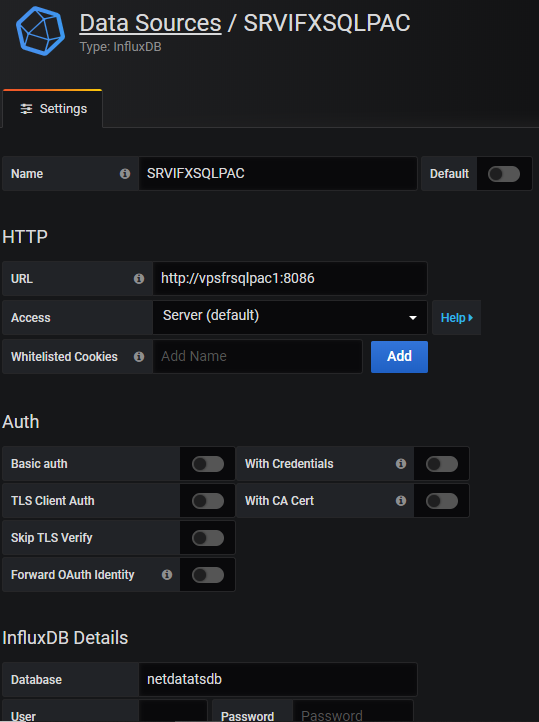
Dans le menu, sélectionner ConfigurationData Sources, cliquer sur le bouton "Add Data Source"
puis choisir "InfluxDB". Renseigner les informations de connexion à la source de données
(http://<hostname>:<port InfluxDB>…) et c’est terminé. La construction de tableaux de bords est intuitive.
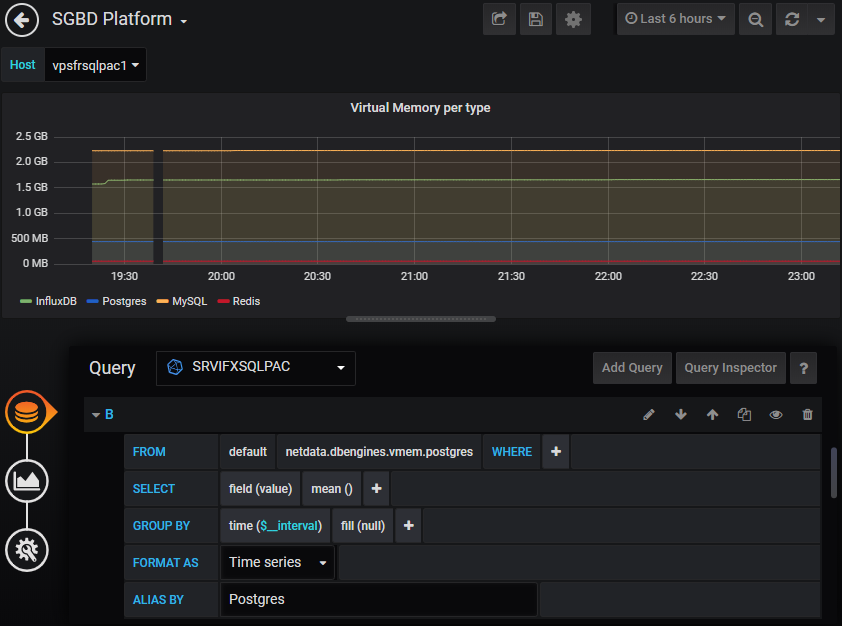
Le plugin pour le langage Flux est en phase beta mais déjà disponible : Flux (InfluxDB) DataSource plugin. Grafana 6.4 et versions supérieures est en pré-requis.
Statistiques et configuration
Utiliser la commande SHOW STATS pour consulter les statistiques. Sans arguments, toutes les statistiques
sont affichées, sauf la taille de l’index In Memory.
Taille de l’index In Memory
SHOW STATS FOR 'indexes'name: indexes memoryBytes ----------- 5438060
Statistiques sur les bases de données
SHOW STATS FOR 'database'name: database tags: database=_internal numMeasurements numSeries --------------- --------- 13 147 name: database tags: database=netdatatsdb numMeasurements numSeries --------------- --------- 2727 4441
Obtenir la taille d’une base de données n’est pas triviale, on peut utiliser SHOW STATS FOR 'shard'
mais la sortie n’est pas très facile à lire, les fragments ne sont pas triés par nom de bases de données :
SHOW STATS FOR 'shard';name: shard tags: database=netdatatsdb, engine=tsm1, id=15, indexType=inmem, path=/sqlpac/influxdb/srvifxsqlpac/data/netdatatsdb/autogen/15, retentionPolicy=autogen, walPath=/sqlpac/influxdb/srvifxsqlpac/wal/netdatatsdb/autogen/15 diskBytes fieldsCreate seriesCreate writeBytes writePointsDropped writePointsErr writePointsOk writeReq writeReqErr writeReqOk --------- ------------ ------------ ---------- ------------------ -------------- ------------- -------- ----------- ---------- 36094696 0 2973 0 0 0 0 0 0 0 name: shard tags: database=netdatatsdb, engine=tsm1, id=22, indexType=inmem, path=/sqlpac/influxdb/srvifxsqlpac/data/netdatatsdb/autogen/22, retentionPolicy=autogen, walPath=/sqlpac/influxdb/srvifxsqlpac/wal/netdatatsdb/autogen/22 diskBytes fieldsCreate seriesCreate writeBytes writePointsDropped writePointsErr writePointsOk writeReq writeReqErr writeReqOk --------- ------------ ------------ ---------- ------------------ -------------- ------------- -------- ----------- ---------- 17649537 0 3422 0 0 0 0 0 0 0 name: shard tags: database=netdatatsdb, engine=tsm1, id=26, indexType=inmem, path=/sqlpac/influxdb/srvifxsqlpac/data/netdatatsdb/autogen/26, retentionPolicy=autogen, walPath=/sqlpac/influxdb/srvifxsqlpac/wal/netdatatsdb/autogen/26 diskBytes fieldsCreate seriesCreate writeBytes writePointsDropped writePointsErr writePointsOk writeReq writeReqErr writeReqOk --------- ------------ ------------ ---------- ------------------ -------------- ------------- -------- ----------- ---------- 110735177 0 3691 0 0 0 0 0 0 0 name: shard tags: database=netdatatsdb, engine=tsm1, id=47, indexType=inmem, path=/sqlpac/influxdb/srvifxsqlpac/data/netdatatsdb/autogen/47, retentionPolicy=autogen, walPath=/sqlpac/influxdb/srvifxsqlpac/wal/netdatatsdb/autogen/47 diskBytes fieldsCreate seriesCreate writeBytes writePointsDropped writePointsErr writePointsOk writeReq writeReqErr writeReqOk --------- ------------ ------------ ---------- ------------------ -------------- ------------- -------- ----------- ---------- 28286352 0 3577 0 0 0 0 0 0 0 name: shard tags: database=netdatatsdb, engine=tsm1, id=58, indexType=inmem, path=/sqlpac/influxdb/srvifxsqlpac/data/netdatatsdb/autogen/58, retentionPolicy=autogen, walPath=/sqlpac/influxdb/srvifxsqlpac/wal/netdatatsdb/autogen/58 diskBytes fieldsCreate seriesCreate writeBytes writePointsDropped writePointsErr writePointsOk writeReq writeReqErr writeReqOk --------- ------------ ------------ ---------- ------------------ -------------- ------------- -------- ----------- ---------- 46062999 234 3294 0 0 0 5699051 7092 0 7092
ou une requête peut être lancée directement dans la base _internal pour filtrer sur le nom de la base
de données.
USE _internal; SELECT last("diskBytes") FROM "monitor"."shard" WHERE ("database" =~/netdatatsdb/) AND time >= now() -1m GROUP BY "database", "path" fill(null);name: shard tags: database=netdatatsdb, path=/sqlpac/influxdb/srvifxsqlpac/data/netdatatsdb/autogen/15 time last ---- ---- 1581030800000000000 36094696 name: shard tags: database=netdatatsdb, path=/sqlpac/influxdb/srvifxsqlpac/data/netdatatsdb/autogen/22 time last ---- ---- 1581030800000000000 17649537 name: shard tags: database=netdatatsdb, path=/sqlpac/influxdb/srvifxsqlpac/data/netdatatsdb/autogen/26 time last ---- ---- 1581030800000000000 110735177 name: shard tags: database=netdatatsdb, path=/sqlpac/influxdb/srvifxsqlpac/data/netdatatsdb/autogen/47 time last ---- ---- 1581030800000000000 28286352 name: shard tags: database=netdatatsdb, path=/sqlpac/influxdb/srvifxsqlpac/data/netdatatsdb/autogen/58 time last ---- ---- 1581030800000000000 44106795
Statistiques par plugin d’entrée (listener)
Quand des listeners sont mis en route pour l’ingestion de données (opentsdb, graphite, udp…), les statistiques par listener sont disponibles : dans l’exemple ci-dessous, opentsdb sur le port 4242 pour l’ingestion des données en provenance de NetData
SHOW STATS for 'opentsdb';name: opentsdb tags: bind=:4242 batchesTx batchesTxFail connsActive connsHandled droppedPointsInvalid httpConnsHandled pointsTx --------- ------------- ----------- ------------ -------------------- ---------------- -------- 7542 0 1 1 0 0 6063674 tlBadFloat tlBadLine tlBadTag tlBadTime tlBytesRx tlConnsActive tlConnsHandled tlPointsRx tlReadErr ---------- --------- -------- --------- --------- ------------- -------------- ---------- --------- 0 0 0 0 462091571 1 1 6063674 0
Requêtes en cours
Des requêtes non optimales peuvent avoir des comportements néfastes sur le moteur InfluxDB (CPU…), utiliser SHOW QUERIES
et KILL QUERY pour arrêter des requêtes qui surconsomment des ressources :
SHOW QUERIESqid query --- ----- 690 SELECT mean(value) AS mean_value FROM netdatatsdb.autogen."netdata.users.cpu.postgres" WHERE time > '1900-01-16T02:30:00.000Z' AND time < '2020-01-16T03:30:00.000Z' AND host = 'vpsfrsqlpac1' GROUP BY time(10s) database duration status -------- -------- ------ netdatatsdb 8m2s runningKILL QUERY 690;
Configuration
Pour consulter la configuration courante :
SHOW DIAGNOSTICS;name: build Branch Build Time Commit Version ------ ---------- ------ ------- 1.7 23bc63d43a8dc05f53afa46e3526ebb5578f3d88 1.7.9 name: config bind-address reporting-disabled ------------ ------------------ 127.0.0.1:8088 false name: config-coordinator log-queries-after max-concurrent-queries max-select-buckets max-select-point max-select-series query-timeout write-timeout ----------------- ---------------------- ------------------ ---------------- ----------------- ------------- ------------- 0s 0 0 0 0 0s 10s name: config-cqs enabled query-stats-enabled run-interval ------- ------------------- ------------ true false 1s name: config-data cache-max-memory-size cache-snapshot-memory-size cache-snapshot-write-cold-duration compact-full-write-cold-duration --------------------- -------------------------- ---------------------------------- -------------------------------- 1073741824 26214400 10m0s 4h0m0s dir max-concurrent-compactions max-index-log-file-size --- -------------------------- ----------------------- /sqlpac/influxdb/srvifxsqlpac/data 0 1048576 max-series-per-database max-values-per-tag series-id-set-cache-size ----------------------- ------------------ ------------------------ 1000000 100000 100 wal-dir wal-fsync-delay ------- --------------- /sqlpac/influxdb/srvifxsqlpac/wal 0s name: config-httpd access-log-path bind-address enabled https-enabled max-connection-limit max-row-limit --------------- ------------ ------- ------------- -------------------- ------------- :8086 true false 0 0 name: config-meta dir --- /sqlpac/influxdb/srvifxsqlpac/meta name: config-monitor store-database store-enabled store-interval -------------- ------------- -------------- _internal true 10s name: config-opentsdb enabled bind-address database retention-policy batch-size batch-pending batch-timeout ------- ------------ -------- ---------------- ---------- ------------- ------------- true :4242 netdatatsdb 1000 5 1s name: config-precreator advance-period check-interval enabled -------------- -------------- ------- 30m0s 10m0s true name: config-retention check-interval enabled -------------- ------- 30m0s true name: config-subscriber enabled http-timeout write-buffer-size write-concurrency ------- ------------ ----------------- ----------------- true 30s 1000 40 name: network hostname -------- vpsfrsqlpac1 name: runtime GOARCH GOMAXPROCS GOOS version ------ ---------- ---- ------- amd64 2 linux go1.12.6 name: system PID currentTime started uptime --- ----------- ------- ------ 1382 2020-02-06T23:37:16.912800481Z 2020-02-06T18:20:27.149884796Z 5h16m49.762915685s
Conclusion
InfluxDB est une base de données Time Series avec des performances et fonctionnalités très intéressantes.
- Ingestion de données simple, nativement ou avec des protocoles courants (OpenTSDB, Graphite…).
- Requêtes "SQL Like".
- Reporting et visualisation faciles avec Grafana ou Chronograf.
Une fonctionnalité utile n’a pas été couverte dans cette introduction : les requêtes en continu (continuous queries). Trop de choses à souligner.
Importante note, actuellement en version beta (Février 2020), InfluxDB v2 va bientôt être livrée et il se peut que la migration ne soit pas si simple :
- Le langage InfluxQL est remplacé par le langage Flux dans cette version. Même si il apporte des nouveautés plus qu’intéressantes par rapport à InfluxQL (jointures, pivots, accès à des données externes…), le langage Flux est plus un langage no-SQL qui n’est pas si évident à apprendre.
- Le support natif des protocoles Graphite, OpenTSDB… est supprimé. L’utilisation de telegraf sera obligatoire.
- Les requêtes continues (Continuous queries) sont remplacées par des "Tasks".