
Introduction
La vitesse des pages est un des critères clés dans les algorithmes de classement des moteurs de recherche Google.
Pour réaliser des audits des pages Web, un outil en ligne utilisant LightHouse est disponible sur Google.com : PageSpeed Insights Online tool.
LightHouse est aussi disponible en tant qu’extension pour Chrome, MAIS, avec l’usage et la pratique on finit par s’apercevoir de résultats non pertinents : des valeurs pour les statistiques "Time to interactive", "Speed index", "First CPU idle", "Max Potential First Input Delay" un peu incroyables comparées à l’expérience et au ressenti utilisateur.
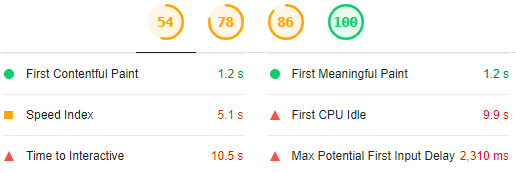
Les statistiques peuvent être surprenantes surtout si le hardware utilisé ne souffre pas de problèmes de performances et qu’elles ne reflètent vraiment pas le ressenti.
Le caractère incroyable de ces valeurs est confirmé par les résultats obtenus avec l’outil en ligne pour une même page, plus réalistes et proches du ressenti utilisateur :

L’extension pour Chrome est très bien adaptée pour auditer des pages Web qui ont besoin d’améliorations notables, mais pas pour du tuning fin.
4 catégories d’audit sur lesquels se concentrer quand on analyse et affine des pages Web :
Les API Google PageSpeed Insights (version 5 à la date de rédaction de cet article) donnent la possibilité d’extraire par programmation les résultats LightHouse exécutés depuis les laboratoires Google.
Avec très peu de lignes de code Python, les statistiques principales peuvent être extraites et stockées dans une table pour historisation : utile lorsqu’on planifie des benchmarks avant/après migrations, mises à niveau.
Septembre 2020 : Article mis à jour avec les nouvelles statistiques CLS (Cumulative Layout Shift) et LCP (Largest Contentful Paint) introduites avec LightHouse 6.
Récupération des résultats des vitesses des pages avec le package requests
Très peu de lignes de code pour extraire les résultats pour une URL donnée, la méthode GET est utilisée :
import requests
def run_pagespeed():
request_url='https://www.sqlpac.com/referentiel/docs/influxdb-v1.7-architecture-installation-configuration-utilisation.html'
apikey='ApIKeYYMNTHtvQ4…'
serviceurl = 'https://www.googleapis.com/pagespeedonline/v5/runPagespeed'
q = { 'url': request_url,
'key': apikey ,
'strategy': 'DESKTOP',
'category':['PERFORMANCE','ACCESSIBILITY','BEST_PRACTICES','SEO'],
'locale': 'fr' }
rj = requests.get(serviceurl, params = q)
def main():
run_pagespeed()
if (__name__=="__main__"):
main()Description des paramètres :
- La clé API est optionnelle : elle est nécessaire si il est prévu d’automatiser les requêtes et de réaliser des requêtes multiples par seconde.
- La stratégie définit l’appareil :
DESKTOPouMOBILE.'strategy': 'DESKTOP' - Les catégories Lighthouse à exécuter. Si aucune catégorie n’est donnée, seule la catégorie performance est évaluée.
Valeurs possibles :
PERFORMANCE,ACCESSIBILITY,BEST_PRACTICES,SEO,PWA(Progressive Web App). PWA n’est pas abordé ici.'category':['PERFORMANCE','ACCESSIBILITY','BEST_PRACTICES','SEO'] - Le paramètre
localedéfinit la langue pour les résultats.'locale': 'fr'
Extraction des métriques
La sortie est très verbeuse. Quelles données à extraire et stocker ?
Préparation des objets
Les résultats sont d’abord transformés en objet dictionnaire avec le package json.
Un dictionnaire nommé p est créé pour stocker les métriques essentiels à extraire et à sauvegarder plus tard dans une table.
import json
…
rj = requests.get(serviceurl, params = q)
if (rj.status_code==200):
fullresults = json.loads(rj.text)
p = {}Quelques méta données sont préparées :
- Date time de la mesure :
%Y-%m-%d %H:%M:%S - Nom du fichier des résultats :
<page>_%Y%m%d%H%M%S.json. Les fichiers résultats seront stockés dans le répertoire$LOG. - Device (strategy) :
D | M, mobile ou ordinateur
from datetime import datetime
…
measuretime = datetime.now()
p['date_measure'] = measuretime.strftime('%Y-%m-%d %H:%M:%S')
p['resultfile'] = '%s_%s.json' % (q['url'].replace('.html','').split('/').pop(), measuretime.strftime('%Y%m%d%H%M%S'))
p['device'] = 'D' if q['strategy'] == 'DESKTOP' else 'M'Les résultats lighthouse sont stockés dans la clé lighthouseResult de la sortie JSON :
"lighthouseResult": { }Le fichier des résultats est sauvegardé uniquement si la clé lighthouseResult existe :
if (fullresults.get('lighthouseResult') != None):
with open(os.getenv('LOG') + '/' + p['resultfile'],'w') as f:
json.dump(fullresults,f,indent=4, ensure_ascii=False)
r = fullresults.get('lighthouseResult')Un dictionnaire intermédiaire r contenant la clé lighthouseResult est créé pour alléger le code source.
Score des catégories
Le score pour chaque catégorie est stocké dans r['categories'][category]['score']:
"lighthouseResult": {
…
"categories": {
"performance": {
"id": "performance",
"title": "Performance",
"score": 0.84,
…
"accessibility": {
"id": "accessibility",
"title": "Accessibility",
"description": "These …",
"score": 0.87,
…
"best-practices": {
"id": "best-practices",
"title": "Best Practices",
"score": 0.92,
…
"seo": {
"id": "seo",
"title": "SEO",
"description": "These …",
"score": 0.92,
…
…
}Ils sont intégrés dans le dictionnaire p :
if (fullresults.get('lighthouseResult') != None):
r = fullresults.get('lighthouseResult')
categories = ['performance', 'accessibility','best-practices','seo']
for category in categories:
try:
p[category] = r['categories'][category]['score']*100
except Exception:
p[category] = 'null'Métriques principales : First Content Full Paint, First CPU Idle …
Les métriques essentielles sont stockées dans la clé r['audits']['metrics']['details']
Dans l’exemple ci-dessous, seules les métriques pertinentes à conserver sont affichées :
"lighthouseResult": {
…
"audits": {
…
"metrics": {
"id": "metrics",
"title": "Metrics",
"description": "Collects all available metrics.",
"details": {
"type": "debugdata",
"items": [
{
"firstContentfulPaint": 601,
"firstMeaningfulPaint": 601,
"largestContentfulPaint": 1920,
"speedIndex": 1661,
"firstCPUIdle": 1137,
"interactive": 3522,
"estimatedInputLatency": 17,
"observedDomContentLoaded": 119,
"observedLoad": 223,
"totalBlockingTime": 39,
"cumulativeLayoutShift": 0.004959294866182179 …
}, …
]Les métriques sont en millisecondes, sauf cumulativeLayoutShift :
firstContentfulPaint: "First Contentful Paint (FCP)" indique le temps au bout duquel le premier bout de texte ou la première image est dessiné.firstMeaningfulPaint: "First Meaningful Paint" mesure quand le contenu primaire d’une page est visible.largestContentfulPaint: nouveauté LightHouse 6, "Largest Contentful Paint (LCP)" marque le moment pendant le chargement de la page lorsque le contenu principal est chargé et visible pour l’utilisateur, une mesure de l’expérience de chargement perçue plus réaliste.speedIndex: L’indice de vitesse indique la rapidité avec laquelle le contenu de la page est visuellement "peuplée" à l’œil.firstCPUIdle: "First CPU Idle" marque le premier temps où le thread principal de la page devient assez calme pour accepter et gérer une action utilisateur (input).interactive: "Time to interactive" est le temps qu’il a fallu pour que la page devienne complètement interactive.estimatedInputLatency: "Estimated Input Latency" est une estimation du temps que met l’application à répondre à une action utilisateur, en millisecondes, durant les 5 premières secondes les plus occupées du chargement de la page. Si la latence est supérieure à 50 ms, les utilisateurs peuvent percevoir l’application comme ayant du retard.observedDomContentLoaded: Durée avant l’évènement DOMContentLoaded.observedLoad: Durée avant l’évènement Load.totalBlockingTime: Somme de tous les temps entre "FCP" et "Time to Interactive", lorsque la tâche excède 50ms, exprimée in millisecondes.cumulativeLayoutShift: nouveauté LightHouse 6, "Cumulative Layout Shift (CLS)" mesure la stabilité visuelle et quantifie à quel point le contenu d’une page se déplace visuellement.
Pour éviter de coder en dur les noms des métriques dans le programme, un fichier JSON de méta données speed-metadata.json est préparé pour spécifier les métriques que l’on souhaite extraire et stocker dans l’objet p :
$CFG/speed-metadata.json
{
"metrics" : [ "firstContentfulPaint","firstMeaningfulPaint","largestContentfulPaint",
"speedIndex","firstCPUIdle","interactive","estimatedInputLatency",
"observedDomContentLoaded","observedLoad",
"totalBlockingTime", "cumulativeLayoutShift" ]
}Alors dans le programme pour alimenter le dictionnaire p:
with open(os.getenv('CFG') + '/speed-metadata.json','r') as m:
metadata = json.load(m)
for s in metadata['metrics']:
try:
p[s] = r['audits']['metrics']['details']['items'][0][s]
except Exception:
p[s] = 'null'Requêtes réseau, taille, ressources
La clé r['audits']['diagnostics']['details'] donne un aperçu très utile du nombre de requêtes, des tailles en bytes, du nombre de tâches, le temps des tâches, le nombre de ressources par type (feuilles de style, scripts, polices …).
Dans l’exemple ci-dessous, seules les métriques à conserver et stocker sont affichées et elles ont été triées manuellement pour faciliter la lecture :
"lighthouseResult": {
…
"audits": {
…
"diagnostics": {
"id": "diagnostics",
"title": "Diagnostics",
"description": "Collection of useful page vitals.",
"details": {
"type": "debugdata",
"items": [
{
"numRequests": 111,
"mainDocumentTransferSize": 14583,
"totalByteWeight": 540297,
"numTasks": 1350,
"numTasksOver10ms": 41,
"numTasksOver25ms": 17,
"numTasksOver50ms": 11,
"numTasksOver100ms": 2,
"numTasksOver500ms": 0,
"totalTaskTime": 1864.1690000000049,
"numFonts": 2,
"numScripts": 33,
"numStylesheets": 10,
"maxServerLatency": null
}
]
}La signification des métriques n’a pas besoin de commentaires, leurs noms sont explicites.
Le fichier de méta données JSON est amélioré pour y ajouter les métriques "diagnostics" :
{
"diagnostics" : [ "numRequests",
"mainDocumentTransferSize", "totalByteWeight",
"numTasks", "totalTaskTime",
"numTasksOver10ms", "numTasksOver25ms", "numTasksOver50ms", "numTasksOver100ms", "numTasksOver500ms",
"numFonts", "numScripts", "numStylesheets", "maxServerLatency" ]
,"metrics" : [ "firstContentfulPaint","firstMeaningfulPaint","largestContentfulPaint",
"speedIndex","firstCPUIdle","interactive","estimatedInputLatency",
"observedDomContentLoaded","observedLoad",
"totalBlockingTime", "cumulativeLayoutShift" ]
}Le programme devient très simple :
with open(os.getenv('CFG') + '/speed-metadata.json','r') as m:
metadata = json.load(m)
sections = ['metrics', 'diagnostics']
for section in sections:
for s in metadata[section]:
try:
p[s] = r['audits'][section]['details']['items'][0][s]
except Exception:
p[s] = 'null'Max Potential First Input Delay
Malheureusement, la mesure "Max Potential First Input Delay" n’est pas dans la clé r['audits']['metrics']['details'] mais il est très important de récupérer également la statistique "Max Potential First Input Delay" statistic. La mesure "Maximum Potential First Input Delay" que les utilisateurs pourraient rencontrer est la durée, en millisecondes, de la tâche la plus longue. Elle est disponible dans la clé r['audits']['max-potential-fid'].
"max-potential-fid": {
"id": "max-potential-fid",
"title": "Max Potential First Input Delay",
…
"score": 0.77,
"numericValue": 172
},
try:
p['maxfid'] = r['audits']['max-potential-fid']['numericValue']
except Exception:
p['maxfid']='null'Third Party - Résumé pour les librairies tierces
Une statistique très très importante à extraire et stocker : les impacts des librairies tierces (outils de partage, Google analytics, Google Ads …) sur les chargements de page. Ces librairies peuvent avoir une très importante influence négative. La méthode de chargement doit parfois être revue pour certaines d’entre elles pour limiter leur impact : mode async, defer, "lazy load" (chargement si l’utilisateur arrive visuellement sur un élément).
Un rapport est disponible dans la clé r['audits']['third-party-summary']['details']['summary']
"lighthouseResult": {
…
"audits": {
…
"third-party-summary": {
"id": "third-party-summary",
"title": "Minimize third-party usage",
"score": 1,
"details": {
"summary": {
"wastedBytes": 219053,
"wastedMs": 11.327000000000005
},La métrique wastedMs donne le temps total en millisecondes durant lequel les librairies tierces ont bloqué le thread principal : très utile pour définir la stratégie async | defer, quand charger la librairie tierce …
La rapport affiche même les détails par librairie tierce ! Excellente fonctionnalité. Attention : dans les détails par item,
mainThreadTime n’est le temps bloquant en millisecondes, mais l’heure de démarrage relatif dans la chronologie du chargement de la page.
"items": [
{
"entity": {
"type": "link",
"text": "Google/Doubleclick Ads",
"url": "https://www.doubleclickbygoogle.com/"
},
"mainThreadTime": 352.3499999999992,
"transferSize": 197607,
"blockingTime": 11.327000000000005
},
{
"entity": {
"type": "link",
"text": "Google Analytics",
"url": "https://www.google.com/analytics/analytics/"
},
"mainThreadTime": 39.71400000000002,
"transferSize": 20064,
"blockingTime": 0
}, …Le résumé pour les librairies tierces est ajouté dans l’extraction :
try:
p['3dpWeight'] = r['audits']['third-party-summary']['details']['summary']['wastedBytes']
p['3dpBlockingTime'] = r['audits']['third-party-summary']['details']['summary']['wastedMs']
except Exception:
p['3dpWeight'] = 'null'
p['3dpBlockingTime'] = 'null'Le programme d’extraction final
Maintenant que les statistiques à extraire sont définies, l’URL complète est ajoutée dans le dictionnaire et un flag est également ajouté afin de mieux identifier une mesure (avant une migration, une mise à jour d’amélioration …),
plus tard ce flag sera renseigné par un argument donné au programme.
La durée du test, disponible dans la clé r['timing'] (ms), est également intégrée :
"lighthouseResult": {
…
"timing": {
"total": 12407.03
}…
p['url'] = q['url']
…
p['flag'] = ''
…
try:
p['duration'] = r['timing']['total']/1000
except Exception:
p['duration'] = 'null'Le programme final ressemble à ceci :
…
if (rj.status_code==200):
fullresults = json.loads(rj.text)
p = {}
measuretime = datetime.now()
p['date_measure'] = measuretime.strftime('%Y-%m-%d %H:%M:%S')
p['url'] = q['url']
p['resultfile'] = '%s_%s.json' % (q['url'].replace('.html','').split('/').pop(), measuretime.strftime('%Y%m%d%H%M%S'))
p['device'] = 'D' if q['strategy'] == 'DESKTOP' else 'M'
p['flag'] = ''
if (fullresults.get('lighthouseResult') != None):
with open(os.getenv('LOG') + '/' + p['resultfile'],'w') as f:
json.dump(fullresults,f,indent=4, ensure_ascii=False)
r = fullresults.get('lighthouseResult')
categories = ['performance', 'accessibility','best-practices','seo']
for category in categories:
try:
p[category] = r['categories'][category]['score']*100
except Exception:
p[category] = 'null'
with open(os.getenv('CFG') + '/speed-metadata.json','r') as m:
metadata = json.load(m)
sections = ['metrics', 'diagnostics']
for section in sections:
for s in metadata[section]:
try:
p[s] = r['audits'][section]['details']['items'][0][s]
except Exception:
p[s] = 'null'
try:
p['maxfid'] = r['audits']['max-potential-fid']['numericValue']
except Exception:
p['maxfid'] = 'null'
try:
p['3dpWeight'] = r['audits']['third-party-summary']['details']['summary']['wastedBytes']
p['3dpBlockingTime'] = r['audits']['third-party-summary']['details']['summary']['wastedMs']
except Exception:
p['3dpWeight'] = 'null'
p['3dpBlockingTime'] = 'null'Le dictionnaire p résultant est alors le suivant pour l’exemple :
{
"date_measure": "2020-05-07 08:40:42",
"url": "https://www.sqlpac.com/referentiel/docs/influxdb-v1.7-architecture-installation-configuration-utilisation.html",
"resultfile": "influxdb-v1.7-architecture-installation-configuration-utilisation_20200509012942.json",
"device": "D",
"flag": "",
"duration": 11.88095,
"performance": 86.0,
"accessibility": 87.0,
"best-practices": 100,
"seo": 100,
"firstContentfulPaint": 520,
"firstMeaningfulPaint": 520,
"largestContentfulPaint": 1920,
"speedIndex": 1417,
"firstCPUIdle": 1381,
"interactive": 3502,
"estimatedInputLatency": 13,
"observedDomContentLoaded": 155,
"observedLoad": 224,
"totalBlockingTime": 57,
"cumulativeLayoutShift": 0.004959294866182179,
"numRequests": 104,
"mainDocumentTransferSize": 14568,
"totalByteWeight": 436237,
"numTasks": 1180,
"totalTaskTime": 1320.9420000000018,
"numTasksOver10ms": 27,
"numTasksOver25ms": 14,
"numTasksOver50ms": 4,
"numTasksOver100ms": 3,
"numTasksOver500ms": 0,
"numFonts": 1,
"numScripts": 31,
"numStylesheets": 10,
"maxfid": 153,
"3dpWeight": 217527,
"3dpBlockingTime": 15.482
}Stockage des résultats
Une fois le dictionnaire prêt, plusieurs options pour stocker les résultats : base de données, fichier …
Les résultats sont stockés dans une base de données MySQL dans ce cas pratique. Le programme Python ne gère pas l’insertion dans la base de données car elle n’est pas ici accessible directement (contraintes dûes à l’hébergement Cloud).
La structure de la table reflète la structure du dictionnaire :
create table perf_pagespeed (
date_measure datetime not null,
url varchar(512) not null,
resultfile varchar(512) not null,
device enum ('D','M') not null,
flag varchar(30) null,
duration float,
performance int(3) null,
accessibility int(3) null,
`best-practices` int(3) null,
seo int(3) null,
firstContentfulPaint int null,
firstMeaningfulPaint int null,
largestContentfulPaint int null, /** nouveauté LightHouse 6 */
speedIndex int null,
firstCPUIdle int null,
interactive int null,
estimatedInputLatency int null,
observedDomContentLoaded int null,
observedLoad int null,
totalBlockingTime int null,
cumulativeLayoutShift float null, /** nouveauté LightHouse 6 */
numRequests int null,
mainDocumentTransferSize int null,
totalByteWeight int null,
numTasks int null,
totalTaskTime float null,
numTasksOver10ms int null,
numTasksOver25ms int null,
numTasksOver50ms int null,
numTasksOver100ms int null,
numTasksOver500ms int null,
numFonts int null,
numScripts int null,
numStylesheets int null,
maxfid int null,
`3dpWeight` int null,
`3dpBlockingTime` int null
)Le programme python envoie le dictionnaire en utilisant la méthode POST du package requests à un page PHP sécurisée par une authentification basique :
requests.post('https://www.sqlpac.com/rpc/rpcu-pagespeed.php', data = p, auth=HTTPBasicAuth('<user>', '************'))
Le programme PHP génère dynamiquement la syntaxe à partir des noms des variables POST reçues et exécute la commande INSERT :
insert into perf_pagespeed (
`date_measure`,
`url`,
`resultfile`,
`device`,
`flag`,
`duration`,
`performance`,`accessibility`,`best-practices`,`seo`,
`firstContentfulPaint`,`firstMeaningfulPaint`,`largestContentfulPaint`,
`speedIndex`,`firstCPUIdle`,`interactive`,`estimatedInputLatency`,
`observedDomContentLoaded`,`observedLoad`,`totalBlockingTime`,
`cumulativeLayoutShift`,
`numRequests`,`mainDocumentTransferSize`,`totalByteWeight`,
`numTasks`,`totalTaskTime`,`numTasksOver10ms`,`numTasksOver25ms`,`numTasksOver50ms`,`numTasksOver100ms`,`numTasksOver500ms`,
`numFonts`,`numScripts`,`numStylesheets`,
`maxfid`,`3dpWeight`,`3dpBlockingTime`)
values (
'2020-05-07 10:39:44',
'https://www.sqlpac.com/referentiel/docs/influxdb-v1.7-architecture-installation-configuration-utilisation.html',
'influxdb-v1.7-architecture-installation-configuration-utilisation_20200509023944.json',
'D',
'',
13.168520000000001,
87.0,87.0,92.0,100,
520,520,1920,
1448,1056,3321,13,
227,338,33,
0.004959294866182179,
104,14583,435780,
1173,1512.4969999999985,39,14,6,1,0,
1,31,10,
116,217042,0)rpcu_pagespeed.php
<?php
require_once('./include/config.inc');
$resp = array();
$conn=mysqli_connect('localhost','sqlpac_rw','********','sqlpacdb',40000);
mysqli_set_charset($conn,"utf8");
if ( ! $conn ) {
$resp[0]["returncode"] = -2;
$resp[0]["reason"] = "Connexion to database issue";
}
else {
$cols="insert into perf_pagespeed (";
$values=" values (";
$i=1;
foreach ($_POST as $key=>$value) {
if ($i > 1) { $cols .= ","; $values .= ","; }
$i++;
$cols .= "`".$key."`";
if (! is_numeric($value)) { $values .= "'"; }
$values .= $value;
if (! is_numeric($value)) { $values .= "'"; }
}
$cols .= ") ";
$values .= ") ";
$sql = $cols." ".$values;
if ( ! mysqli_query($conn,$sql) ) {
$resp[0]["returncode"] = -2;
$resp[0]["errorcode"] = mysqli_errno($conn);
$resp[0]["reason"] = mysqli_error($conn);
} else {
$resp[0]["returncode"] = mysqli_affected_rows($conn);
$resp[0]["url"] = $_POST["url"];
$resp[0]["datets"] = $_POST["date_measure"];
}
mysqli_close($conn);
}
print json_encode($resp);
?>Amélioration du programme
Le programme appelé speed.py est amélioré en ajoutant des arguments et des iterations possibles
sqlpac@vpsfrsqlpac2$ python3 speed.py --helpusage: speed.py [-h] -p PAGE [-m] [-o LOCALE] [-i ITERATION] optional arguments: -h, --help show this help message and exit -p PAGE, --page PAGE Page -m, --mobile Device mobile -o LOCALE, --locale LOCALE Output language results -i ITERATION, --iteration ITERATION Number of iterations -f FLAG, --flag FLAG Identifier flag
Pour implémenter les arguments :
import argparse
…
def run_pagespeed():
…
q = { 'url': args.page,
'key': apikey ,
'strategy': args.device,
'category':['PERFORMANCE','ACCESSIBILITY','BEST_PRACTICES','SEO'],
'locale': args.locale }
…
p['url'] = args.page
…
p['device'] = 'D' if args.device=='DESKTOP' else 'M'
p['flag'] = args.flag
…
def run_args():
mparser= argparse.ArgumentParser()
mparser.add_argument('-p','--page', help='Page', required=True)
mparser.add_argument('-m','--mobile', help='Device mobile', action='store_false')
mparser.add_argument('-o','--locale', help='Output language results', default='en')
mparser.add_argument('-i','--iteration', help='Number of iterations', default=1, type=int)
mparser.add_argument('-f','--flag', help='Identifier flag', default='')
global args
args = mparser.parse_args()
def main():
run_args()
args.device='DESKTOP' if args.mobile!=False else 'MOBILE'
i=1
while i <= args.iteration:
run_pagespeed()
i += 1
if (__name__=="__main__"):
main()Un exemple d’appel : 20 itérations, test sur mobile avec le flag "before mig 5.9"
python3 speed.py -i 20 -m -f "before mig 5.9" \
-p https://www.sqlpac.com/referentiel/docs/influxdb-v1.7-architecture-installation-configuration-utilisation.htmlCas d’utilisation
Une librairie framework est migrée de la version 5.8 vers la version 5.9 avec des améliorations de performances. Des benchmarks pour le device desktop sont enregistrés avant et après pour la page
https://www.sqlpac.com/referentiel/docs/influxdb-v1.7-architecture-installation-configuration-utilisation.html :
python3 speed.py -p <influxdb-v1.7-architecture-installation-configuration-utilisation.html> \
-i 40 -f "Version 5.8"python3 speed.py -p <influxdb-v1.7-architecture-installation-configuration-utilisation.html> \
-i 40 -f "Version 5.9"Le score Performance passe de 75% à 86%.
SELECT
flag,
AVG(performance) AS performance,
AVG(accessibility) AS accessibility,
AVG(`best-practices`) AS `best-practices`,
AVG(seo) AS seo,
AVG(speedindex) AS speedindex,
AVG(firstCPUIdle ) AS firstCPUIdle,
AVG(interactive) AS interactive,
AVG(totalBlockingTime) AS totalBlockingTime,
AVG(observedDomContentLoaded) AS observedDomContentLoaded,
AVG(observedLoad) AS observedLoad,
AVG(3dpWeight) AS 3dpWeight,
AVG(3dpBlockingTime) AS 3dpBlockingTime
FROM perf_pagespeed
WHERE flag IN ('Version 5.8','Version 5.9')
GROUP BY flagDans ce cas d’utilisation, la performance a été radicalement améliorée en différant le chargement de la librairie tierce Disqus uniquement lorsque l’utilisateur arrive visuellement à la section "Commentaires". Elle a été facilement identifée dans les fichiers JSON des résultats d’audit :
"third-party-summary": {
"id": "third-party-summary",
"title": "Minimize third-party usage",
"description": "Third-party code can significantly impact load performance. Limit the number of redundant third-party providers and try to load third-party code after your page has primarily finished loading. [Learn more](https://developers.google.com/web/fundamentals/performance/optimizing-content-efficiency/loading-third-party-javascript/).",
…
"details": {
"summary": {
"wastedBytes": 956402,
"wastedMs": 109.181
},
…
"type": "table",
"items": [
{
"transferSize": 566804,
"blockingTime": 109.181,
"entity": {
"url": "http://disqus.com/",
"text": "Disqus",
"type": "link"
},
"mainThreadTime": 573.4169999999991
},