
Introduction
De manière très discrète est apparue avec Sybase Adaptive Server Enterprise
15.0.3 une nouvelle option de la commande create table :
l’option "for load". L’option for load permet de pouvoir mettre en œuvre
le mécanisme bcp fast load lors du chargement des données. Toute l’information
en ligne relative à cette nouvelle option figure dans les quelques lignes
suivantes :
Adaptive Server Enterprise 15.0.3New Features GuideSystem changesChanged Commands create table
create table
The table you create with this option is available only to BCP IN
and 'alter table unpartition' operations.
For example:
1. Create a table, called TAB:
create table
TAB (col1 int, col2 int, col3 char(50)) partition by roundrobin 3 for load
TAB is unavailable to any user activities until it is unpartitioned,
2. Load the data into TAB, using BCP IN.
3. Unpartition TAB. TAB is now available for any user activities.Cette nouveauté est relative au chargement de données en mode parallèle sur des tables partitionnées.
Le présent document va décrire quelques techniques de chargement parallèles et montrer quel type de gains on peut espérer de cette commande.
Conditions du test
TBL_DEMO est une table de taille moyenne de 800Mb environ permettant
néanmoins de mesurer des comportements significatifs. Voici ses
caractéristiques :
optdiag statistics test..TBL_DEMOStatistics for table: " TBL_DEMO " Data page count: 43764 Empty data page count: 0 Data row count: 182773.0000000000000000 Forwarded row count: 0.0000000000000000 Deleted row count: 0.0000000000000000 Data page CR count: 5475.0000000000000000 OAM + allocation page count: 697 First extent data pages: 0 Data row size: 330.5000000000000000
L’import est réalisé avec le binaire bcp en mode caractère (option -c) et
par paquets de 8K ( option -A 8192 ).
Trois tests différents vont être réalisés successivement à trois reprises, le temps moyen est pris en compte dans chacun des cas.
Test #1 : bcp classique sur la table TBL_DEMO non partitionnée
test1.ksh
#!/bin/ksh
# Creation de la table TBL_DEMO
isql -Uxxx -Pxxx -Dtest -i ddl.sql
# Import classique par bcp dans la table TBL_DEMO
time (
bcp test..TBL_DEMO in TBL_DEMO.bcpc -c -Uxxx -Pxxx -A 8192 -b 10000 &
wait
)ddl.sql
…
CREATE TABLE TBL_DEMO ( … )
goTest #2 : bcp sur la table TBL_DEMO partitionnée en 4 sans l’option for load
test2.ksh
#!/bin/ksh
# Decoupe du fichier TBL_DEMO.bcpc en 4 fichiers avec nawk
nawk -f split.awk TBL_DEMO.bcpc
# Creation de la table TBL_DEMO (partition 4)
isql -Uxxx -Pxxx -Dtest -i ddl_part.sql
# Import en parallèle par bcp dans la table TBL_DEMO
time (
bcp test..TBL_DEMO:1 in TBL_DEMO_1.bcpc -c -Uxxx -Pxxx -A 8192 -b 10000 &
bcp test..TBL_DEMO:2 in TBL_DEMO_2.bcpc -c -Uxxx -Pxxx -A 8192 -b 10000 &
bcp test..TBL_DEMO:3 in TBL_DEMO_3.bcpc -c -Uxxx -Pxxx -A 8192 -b 10000 &
bcp test..TBL_DEMO:4 in TBL_DEMO_4.bcpc -c -Uxxx -Pxxx -A 8192 -b 10000 &
wait
)
# Suppression du partitionnement de la table TBL_DEMO
time isql -Uxxx -Pxxx -Dtest -i ddl_unpart.sql
ddl_part.sql
…
CREATE TABLE TBL_DEMO ( … ) partition by roundrobin 4
goddl_unpart.sql
…
ALTER TABLE TBL_DEMO unpartition
goTest #3 : bcp sur la table TBL_DEMO partitionnée en 4 et créée avec l’option for load
test3.ksh
#!/bin/ksh
# Decoupe du fichier TBL_DEMO.bcpc en 4 fichiers avec nawk
nawk -f split.awk TBL_DEMO.bcpc
# Creation de la table TBL_DEMO (partition 4) avec l’option for load
isql -Uxxx -Pxxx -Dtest -i ddl_part_load.sql
# Import en parallèle par bcp dans la table TBL_DEMO
time (
bcp test..TBL_DEMO:1 in TBL_DEMO_1.bcpc -c -Uxxx -Pxxx -A 8192 -b 10000 &
bcp test..TBL_DEMO:2 in TBL_DEMO_2.bcpc -c -Uxxx -Pxxx -A 8192 -b 10000 &
bcp test..TBL_DEMO:3 in TBL_DEMO_3.bcpc -c -Uxxx -Pxxx -A 8192 -b 10000 &
bcp test..TBL_DEMO:4 in TBL_DEMO_4.bcpc -c -Uxxx -Pxxx -A 8192 -b 10000 &
wait
)
# Suppression du partitionnement de la table TBL_DEMO
time isql -Uxxx -Pxxx -Dtest -i ddl_unpart.sqlddl_part_load.sql
…
CREATE TABLE TBL_DEMO ( … ) partition by roundrobin 4 for load
goRésultats
| test | split | bcp in | unpartition | total | % total | total db | % total db |
|---|---|---|---|---|---|---|---|
| test1 | 0 |
315 |
0 |
315 |
128% |
315 |
230% |
| test2 | 110 |
135 |
139 |
384 |
155% |
274 |
200% |
| test3 | 110 |
135 |
2 |
247 |
100% |
137 |
100% |
| (s) | 0 |
135 |
0 |
247 |
100% |
137 |
100% |
les mesures sont exprimées en secondes dans le graphique ci-dessous
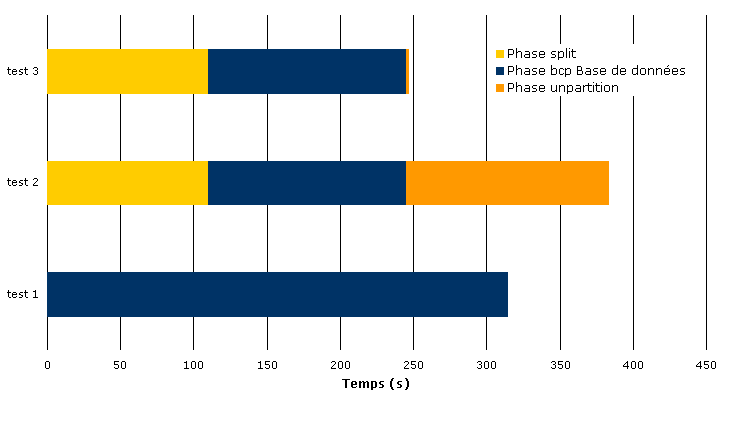
L’option for load est doublement efficace, la durée totale de l’opération
est réduite de près de 30 % et l’activité en base est réduite de plus de la
moitié. Dans le cas présent, l’import classique est 2,3 fois plus long.
L’option for load rend quasi négligeable la phase unpartition en temps de
traitement en base.
À noter que l’option originale d’import en parallèle sans l’option for load,
quoique plus longue en temps absolu reste néanmoins intéressante en terme
d’activité en base par rapport à un import classique sur la table non
partitionnée.
Une restriction à prendre en compte concerne l’accès à la table. Il est tout
simplement impossible de sélectionner le contenu de la table créée avec
l’option for load tant que les commandes bcp in et/ou unpartition n’ont pas été
lancées.
select * from TBL_DEMO goMsg 8243, Level 16, State 3 Server 'SQL_T1_ASE', Line 1 The object 'TBL_DEMO' in database 'test' is created for loading the data using fast load mechanism and is available only to 'bcp in' and 'alter table unparition'. Please retry your query after 'alter table unpartition' on the object.
Le message ne peut pas être plus explicite, message qui indique par ailleurs
que le mécanisme "fast load" est utilisée pour le chargement des données.
Script split.awk
La commande naturelle sous Solaris pour découper un fichier en 4 est split.
Celle-ci n’apparaît pas très efficace, aussi une fonction équivalente a été
mise en œuvre avec nawk et utilisée ici. En voici le code source.
split.awk
# ############################################################################
# @(#) Fichier : split.awk
# @(#) Auteur : FAF
# @(#) Cree le : 02/03/2009
# @(#) Objet : Partitionne un fichier texte en 4 elements de meme taille
# ############################################################################
# ############################################################################
# Fonctions
function getFileName() {
FILEID++
file=prefix "_" FILEID "." suffix
print file
printf "" > file
return file
}
# ############################################################################
# BEGIN
BEGIN {
# -- recuperation du prefixe et suffixe ------------------------------
split(FILENAME,tmp,".")
prefix=tmp[1]
suffix=tmp[2]
# -- Compte du nombre de lignes --------------------------------------
"wc -l " FILENAME | getline
lines=int($1/4)+1
# -- Un peu d info ---------------------------------------------------
printf "Le fichier %s contient %d lignes -> 4 fichiers de %d ln\n", FILENAME, $1, lines
# -- Determination du premier fichier --------------------------------
FILEID=0
FILE=getFileName()
}
# ############################################################################
# Programme
{
print $0 >> FILE
if ( ( NR % lines ) == 0 ) {
close(FILE)
FILE=getFileName()
}
}
# ############################################################################
# ENDDans le cas présent, la découpe du fichier de 800Mb dure moins de 2 minutes avec le binaire nawk contre 3'30s avec le binaire split original.