
Introduction
Le nouveau langage Flux dans InfluxDB v2 résout un bon nombre de limitations du langage InfluxQL.
Voyons quelques fonctionnalités désormais possibles avec le langage Flux sur les données time series : jointures, pivots, histogrammes…
Dans la plupart des sujets, des cas d’utilisation réels sont abordés : joindre des données lorsque les horodatages diffèrent de quelques secondes,
simuler une jointure externe en attendant les nouvelles méthodes de jointure à venir (left, right…), construire des histogrammes sans données cumulatives mais la différence…
L’exploitation des sources de données SQL dans le langage Flux n’est pas abordée ici, ce thème mérite un article dédié : InfluxDB v2, le langage Flux et les bases de données SQL
- Pour les débutants dans le langage Flux habitués à InfluxQL : InfluxDB - Passer du langage InfluxQL au langage Flux
- Les sections de cet article sont également synthétisées dans un aide-mémoire/guide pratique : InfluxDB v2 : langage Flux, aide-mémoire
InfluxDB v2, Rappels rapides
Format de sortie
Il est important de comprendre le format brut des données en sortie avec InfluxDB v2, différent du format de sortie de la v1. Dans la sortie ci-dessous, un filtre n’est défini que sur le nom de la mesure, les filtres sur les clés des tags et des champs (tag keys/field keys) ne sont pas appliqués.
from(bucket: "netdatatsdb/autogen")
|> range(start: -1d)
|> filter(fn: (r) => r._measurement == "vpsmetrics")
|> yield()table _start _stop _time _value _field _measurement host location
----- -------------------- --------------------- ------------------------------ ------ ------ ------------ ------------ --------
0 2021-02-05T00:00:00Z 2021-02-05T23:59:00Z 2021-02-05T03:00:06.446501067Z 1182 mem vpsmetrics vpsfrsqlpac1 france
0 2021-02-05T00:00:00Z 2021-02-05T23:59:00Z 2021-02-05T03:00:16.604175869Z 817 mem vpsmetrics vpsfrsqlpac1 france
…
1 2021-02-05T00:00:00Z 2021-02-05T23:59:00Z 2021-02-05T03:00:06.446501067Z 62 pcpu vpsmetrics vpsfrsqlpac1 france
1 2021-02-05T00:00:00Z 2021-02-05T23:59:00Z 2021-02-05T03:00:16.604175869Z 66 pcpu vpsmetrics vpsfrsqlpac1 france
…
2 2021-02-05T00:00:00Z 2021-02-05T23:59:00Z 2021-02-05T03:00:07.420674651Z 429 mem vpsmetrics vpsfrsqlpac2 france
2 2021-02-05T00:00:00Z 2021-02-05T23:59:00Z 2021-02-05T03:00:17.176860469Z 464 mem vpsmetrics vpsfrsqlpac2 france
…
3 2021-02-05T00:00:00Z 2021-02-05T23:59:00Z 2021-02-05T03:00:07.420674651Z 29 pcpu vpsmetrics vpsfrsqlpac2 france
3 2021-02-05T00:00:00Z 2021-02-05T23:59:00Z 2021-02-05T03:00:17.176860469Z 32 pcpu vpsmetrics vpsfrsqlpac2 france- Un identifiant de table est appliqué sur chaque jeu de résultats.
- L’intervalle de temps est clairement décrit avec les colonnes
_startet_stop. - Le nom de la mesure est dans la colonne
_measurement. - La clé de champ (field key) et sa valeur sont respectivement dans les colonnes
_fieldet_value. - Les clés de tag (tag keys) sont affichées à la fin.
Les colonnes peuvent être supprimées avec les fonctions drop ou keep,
on peut ne pas vouloir toutes les colonnes dans le format de sortie des données brutes.
|> keep(columns: ["_value", "_time"]) |> drop(fn: (column) => column =~ /^_(start|stop)/)Les colonnes sont renommées avec la fonction rename :
|> keep(columns: ["_value", "_time"])
|> rename(columns: {_value: "pcpu", _time: "when"})Interrogation des données
Dans cet article, les requêtes Flux sont exécutées avec l’une des 2 méthodes suivantes :
- Client
influxen ligne de commandes. - GUI InfluxDB v2 intégré
https://<host-influxdb>:8086(anciennement Chronograf dans la suite Tick InfluxDB v1).
Client influx
$ influx query --file query.fluxAvant de pouvoir utiliser le client influx, la config (url, token, org…) est d’abord définie.
$ export INFLUX_CONFIGS_PATH=/sqlpac/influxdb/srvifx2sqlpac/configs
$ export INFLUX_ACTIVE_NAME=default/sqlpac/influxdb/srvifx2sqlpac/configs :
[default]
url = "https://vpsfrsqlpac:8086"
token = "K2YXbGhIJIjVhL…"
org = "sqlpac"
active = trueInterface graphique utilisateur InfluxDB v2
Dans le GUI InfluxDB : utiliser le bouton bascule "View Raw Data" pour afficher les jeux de résultats bruts des requêtes.
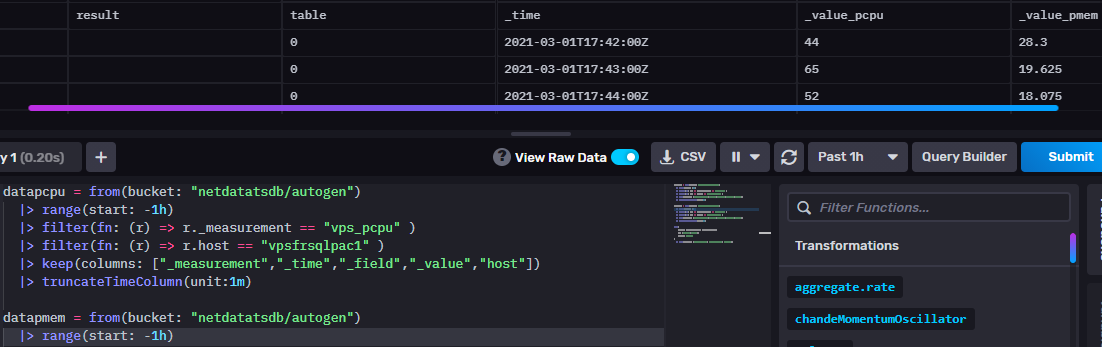
Jointures - join
Dans le cas pratique, les pourcentages de cpu et de mémoire utilisés par machine sont stockés respectivement dans les mesures vps_cpu et
vps_pmem :
_measurement _time _field _value host
------------ ------------------------------ ------ ------ ------------
vps_pcpu 2021-03-01T17:22:10.009239717Z pcpu 63 vpsfrsqlpac1
vps_pcpu 2021-03-01T17:23:10.459116034Z pcpu 73 vpsfrsqlpac1
vps_pcpu 2021-03-01T17:24:10.938936764Z pcpu 57 vpsfrsqlpac1_measurement _time _field _value host
------------ ------------------------------ ------ ------ ------------
vps_pmem 2021-03-01T17:22:10.095918231Z pmem 26.8 vpsfrsqlpac1
vps_pmem 2021-03-01T17:23:10.575832095Z pmem 29.725 vpsfrsqlpac1
vps_pmem 2021-03-01T17:24:11.011812310Z pmem 22.325 vpsfrsqlpac1En lisant la documentation, on conclut : c’est facile de joindre les données avec la fonction join !
datapcpu = from(bucket: "netdatatsdb/autogen")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "vps_pcpu" )
|> filter(fn: (r) => r.host == "vpsfrsqlpac1" )
|> keep(columns: ["_measurement","_time","_field","_value","host"])
datapmem = from(bucket: "netdatatsdb/autogen")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "vps_pmem" )
|> filter(fn: (r) => r.host == "vpsfrsqlpac1" )
|> keep(columns: ["_measurement","_time","_field","_value","host"])
join(
tables: {pcpu:datapcpu, pmem:datapmem},
on: ["_time","host"],
method: "inner"
)
|> keep(columns: ["_value_pmem", "_value_pcpu", "_time"])En exécutant la requête : pas de résultats ! Pourquoi ?
Normalisation des timestamps irréguliers
Dans les systèmes réels, faire une jointure sur les colonnes _time est toujours problématique.
La colonne _time stocke généralement secondes, millisecondes, microsecondes… lesquelles sont très légérement différentes pour joindre 2 points.
Première solution : utiliser la fonction truncateTimeColumn pour normaliser les timestamps irréguliers. Cette fonction tronque
toutes les valeurs _time à une unité indiquée. Dans l’exemple ci-dessous, les valeurs _time sont tronquées à la minute : la jointure fonctionne.
datapcpu = from(bucket: "netdatatsdb/autogen") |> range(start: -1h) |> filter(fn: (r) => r._measurement == "vps_pcpu" ) |> filter(fn: (r) => r.host == "vpsfrsqlpac1" ) |> keep(columns: ["_measurement","_time","_field","_value","host"]) |> truncateTimeColumn(unit:1m) datapmem = from(bucket: "netdatatsdb/autogen") |> range(start: -1h) |> filter(fn: (r) => r._measurement == "vps_pmem" ) |> filter(fn: (r) => r.host == "vpsfrsqlpac1" ) |> keep(columns: ["_measurement","_time","_field","_value","host"]) |> truncateTimeColumn(unit:1m) join( tables: {pcpu:datapcpu, pmem:datapmem}, on: ["_time","host"], method: "inner" ) |> keep(columns: ["_value_pmem", "_value_pcpu", "_time"])_time:time _value_pcpu:float _value_pmem:float ------------------------------ ---------------------------- ---------------------------- 2021-03-01T17:22:00.000000000Z 63 26.8 2021-03-01T17:23:00.000000000Z 73 29.725 2021-03-01T17:24:00.000000000Z 57 22.325
Si elle est techniquement et fonctionnellement acceptable, la fonction aggregateWindow est une autre solution alternative.
datapcpu = from(bucket: "netdatatsdb/autogen") |> range(start: -1h) |> filter(fn: (r) => r._measurement == "vps_pcpu" ) |> filter(fn: (r) => r.host == "vpsfrsqlpac1" ) |> keep(columns: ["_measurement","_time","_field","_value","host"]) |> aggregateWindow(every: 1m, fn: mean) datapmem = from(bucket: "netdatatsdb/autogen") |> range(start: -1h) |> filter(fn: (r) => r._measurement == "vps_pmem" ) |> filter(fn: (r) => r.host == "vpsfrsqlpac1" ) |> keep(columns: ["_measurement","_time","_field","_value","host"]) |> aggregateWindow(every: 1m, fn: mean) join( tables: {pcpu:datapcpu, pmem:datapmem}, on: ["_time","host"], method: "inner" ) |> keep(columns: ["_value_pmem", "_value_pcpu", "_time"])_time:time _value_pcpu:float _value_pmem:float ------------------------------ ---------------------------- ---------------------------- 2021-03-01T17:23:00.000000000Z 63 26.8 2021-03-01T17:24:00.000000000Z 73 29.725 2021-03-01T17:25:00.000000000Z 57 22.325
Méthodes de jointures, limitations
Dans la cas d’utilisation précédent, la jointure est réalisée en utilisant la méthode inner.
join(
tables: {pcpu:datapcpu, pmem:datapmem},
on: ["_time","host"],
method: "inner"
)Seule la méthode inner est actuellement autorisée (v 2.0.4).
Dans les futures versions, d’autres méthodes de jointures seront progressivement implémentées : cross, left, right, full.
Une autre limitation : les jointures ne peuvent avoir actuellement que 2 parents. Cette limite devrait être étendue dans des releases futures également.
Comment gérer les jointures externes (outer joins) en attendant que les autres méthodes soient prêtes ?
La combinaison des fonctions aggregateWindow et fill est une solution de contournement potentielle pour gérer les jointures externes pour le moment.
La fonction fill remplace les valeurs NULL par une valeur par défaut, la valeur par défaut va dépendre du contexte technique et du rendu désiré (graphiques…).
| Valeur précédente | Valeur fixe |
|---|---|
|
|
datapcpu = from(bucket: "netdatatsdb/autogen") |> range(start: -1h) |> filter(fn: (r) => r._measurement == "vps_pcpu" ) |> filter(fn: (r) => r.host == "vpsfrsqlpac1" ) |> keep(columns: ["_measurement","_time","_field","_value","host"]) |> aggregateWindow(every: 1m, fn: mean) |> fill(column: "_value", value: 0.0) datapmem = from(bucket: "netdatatsdb/autogen") |> range(start: -1h) |> filter(fn: (r) => r._measurement == "vps_pmem" ) |> filter(fn: (r) => r.host == "vpsfrsqlpac1" ) |> keep(columns: ["_measurement","_time","_field","_value","host"]) |> aggregateWindow(every: 1m, fn: mean) |> fill(column: "_value", value: 0.0) join( tables: {pcpu:datapcpu, pmem:datapmem}, on: ["_time","host"] ) |> keep(columns: ["_value_pmem", "_value_pcpu", "_time"])_time:time _value_pcpu:float _value_pmem:float ------------------------------ ---------------------------- ---------------------------- 2021-03-01T18:23:00.000000000Z 76 26 2021-03-01T18:24:00.000000000Z 63 24.65 2021-03-01T18:25:00.000000000Z 54 0.0 2021-03-01T18:26:00.000000000Z 69 0.0 2021-03-01T18:27:00.000000000Z 61 0.0 2021-03-01T18:28:00.000000000Z 79 23.4 2021-03-01T18:29:00.000000000Z 65 21.8
Pivot
Le format de sortie par défaut n’est pas vraiment facile pour certains traitements ultérieurs (écrire dans une autre mesure, une base de données SQL…).
from(bucket: "netdatatsdb/autogen") |> range(start: -1h) |> filter(fn: (r) => r._measurement == "vps_pcpumem" and r.host == "vpsfrsqlpac1" ) |> keep(columns: ["_measurement","_time","_field","_value","host"])Table: keys: [_field, _measurement, host] _field:string _measurement:string host:string _time:time _value:float ------------------ ---------------------- ---------------------- ------------------------------ ------------------- mem vps_pcpumem vpsfrsqlpac1 2021-03-01T18:50:46.919579473Z 1055 mem vps_pcpumem vpsfrsqlpac1 2021-03-01T18:51:47.359821389Z 1069 … … … … … Table: keys: [_field, _measurement, host] _field:string _measurement:string host:string _time:time _value:float ------------------ ---------------------- ---------------------- ------------------------------ ------------------- pcpu vps_pcpumem vpsfrsqlpac1 2021-03-01T18:50:46.919579473Z 68 pcpu vps_pcpumem vpsfrsqlpac1 2021-03-01T18:51:47.359821389Z 57 … … … … …
Pivoter les données pour formater la sortie était une fonctionnalité majeure manquante avec InfluxQL. Fonctionnalité prête et facile à utiliser dans le langage Flux :
from(bucket: "netdatatsdb/autogen") |> range(start: -1h) |> filter(fn: (r) => r._measurement == "vps_pcpumem" and r.host == "vpsfrsqlpac1") |> keep(columns: ["_measurement","_time","_field","_value","host"]) |> pivot( rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value" )Table: keys: [_measurement, host] _measurement:string host:string _time:time mem:float pcpu:float ---------------------- --------------- ------------------------------ ------------------- --------------------- vps_pcpumem vpsfrsqlpac1 2021-03-01T18:50:46.919579473Z 1055 68 vps_pcpumem vpsfrsqlpac1 2021-03-01T18:51:47.359821389Z 1069 57 … … … … …
Comme pour les jointures, si besoin, utiliser la fonction truncateTimeColumn pour normaliser les timestamps.
Utiliser la fonction de raccourci schema.fieldsAsCols() lorsque le pivot de données est fait sur _time/_field :
import "influxdata/influxdb/schema"
from(bucket: "netdatatsdb/autogen")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "vps_pcpumem" and
r.host == "vpsfrsqlpac1" )
|> keep(columns: ["_measurement","_time","_field","_value","host"])
|> schema.fieldsAsCols()Histogrammes
Produire des histogrammes par une requête est devenu simple dans le langage Flux avec ses fonctions histogram et linearBins.
La fonction linearBins facilite la création de la liste des floats séparés linéairement ([0.0,5.0,10.0,15.0,…]).
from(bucket:"netdatatsdb/autogen") |> range(start: -1d) |> filter(fn: (r) => r._measurement == "vps_pcpumem" and r.host == "vpsfrsqlpac1" and r._field == "pcpu" ) |> histogram( bins: linearBins(start: 0.0, width: 5.0, count: 21, infinity: false) ) |> keep(columns: ["le","_value"])le:float _value:float ---------------------------- ---------------------------- 0 0 5 0 10 0 15 0 20 0 25 0 30 0 35 0 40 42 45 206 50 389 55 547 60 716 65 910 70 1085 75 1260 80 1427 85 1427 90 1427 95 1427 100 1427
Une colonne le (less or equals) est automatiquement créée, dans la colonne _value les données sont cumulatives.
Appliquer la fonction difference pour annuler le mode cumulatif et ainsi construire un histogramme typique.
|> histogram( bins: linearBins(start: 0.0, width: 5.0, count: 21, infinity: false) ) |> difference() |> keep(columns: ["le","_value"])le:float _value:float ---------------------------- ---------------------------- 5 0 10 0 15 0 20 0 25 0 30 0 35 0 40 42 45 161 50 183 55 156 60 172 65 195 70 175 75 175 80 169 85 0 90 0 95 0 100 0
Le mode logarithmique est réalisé avec la fonction logarithmicBins.
|> histogram(
bins: logarithmicBins(start: 1.0, factor: 2.0, count: 10,
infinity: false)La fonction histogram présente un intérêt quand on a besoin de construire des histogrammes par programmation pour des traitements ultérieurs.
L’interface graphique InfluxDB ou Grafana n’a en fait pas besoin de la fonction histogram.
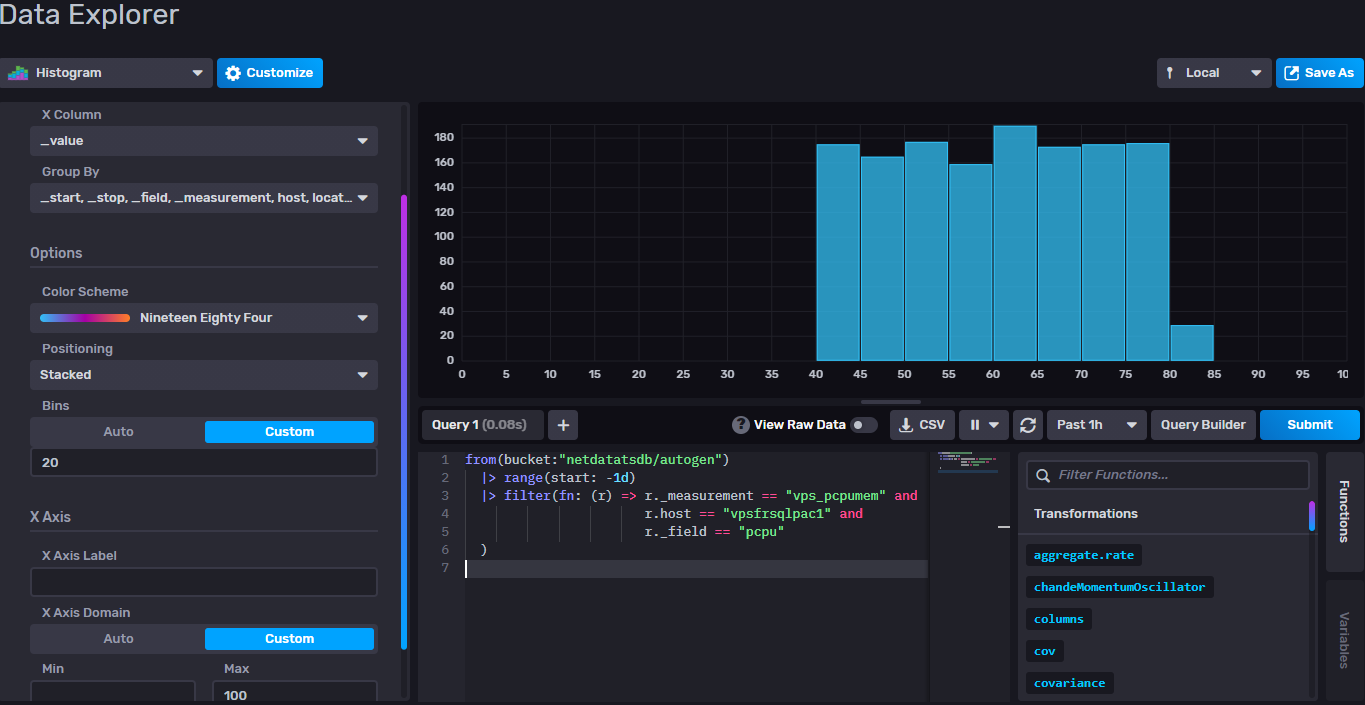
Dans le GUI InfluxDB, pour visualiser un histogramme :
- La requête source sans l’appel de la fonction
histogramest utilisée.from(bucket:"netdatatsdb/autogen") |> range(start: -1d) |> filter(fn: (r) => r._measurement == "vps_pcpumem" and r.host == "vpsfrsqlpac1" and r._field == "pcpu" ) - Sélectionner le type de graphique "Histogram" et cliquer sur le bouton "Customize".
- Définir la colonne X (
_value), le nombre de bacs appelés communément "bins" (20) et la valeur max de X (100).
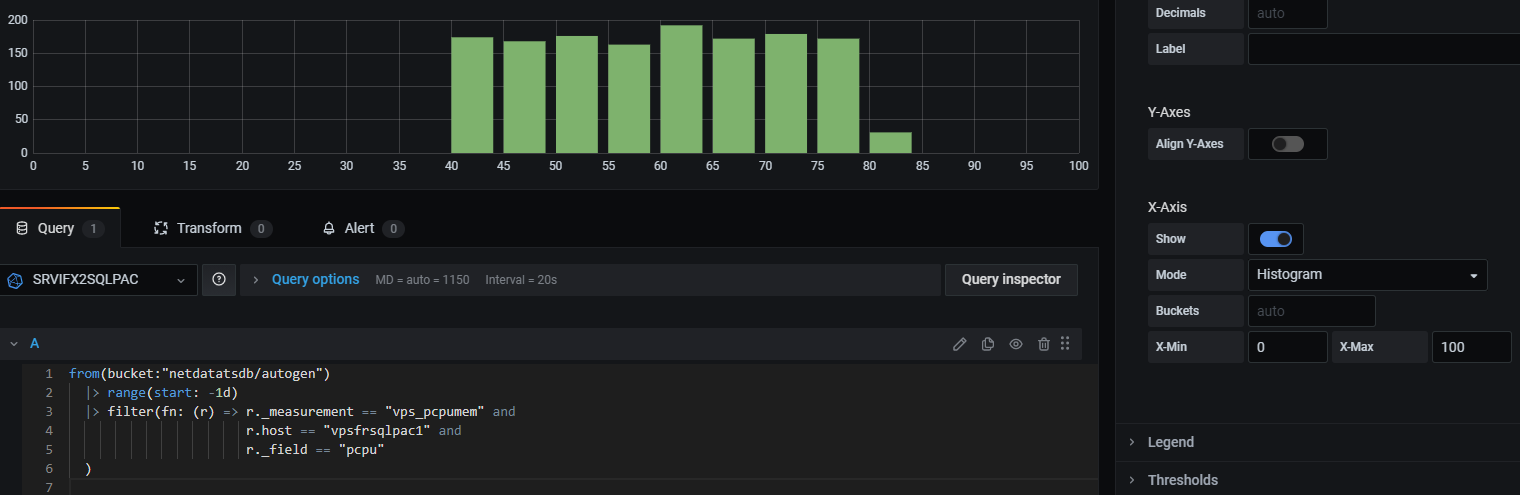
Dans Grafana, même méthodologie, la requête source sans l’appel de la fonction histogram est utilisée.
Colonnes calculées (Computed columns) - map
Les colonnes calculées sont créées avec la fonction map. La fonction map est très généralement appelée après une opération de jointure ou de pivot.
Dans l’exemple ci-dessous, la mesure vps_space stocke 2 champs par point : l’espace utilisé (used) et l’espace disponible (available).
Dans le jeu de résultats final, on veut calculer le pourcentage d’espace utilisé dans une colonne appelée pctspace :
from(bucket: "netdatatsdb/autogen") |> range(start: -1d) |> filter(fn: (r) => r._measurement == "vps_space" and r.host == "vpsfrsqlpac1" and (r._field == "used" or r._field == "available") ) |> pivot( rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value" ) |> map(fn: (r) => ({ r with pctspace: (r.used / (r.used + r.available)) * 100.0 })) |> keep(columns: ["_time", "pctspace"])_time:time pctspace:float ------------------------------ ---------------------------- 2021-03-01T17:51:47.437958334Z 73.84712268752916 2021-03-01T17:52:47.900410821Z 73.84713257521788 2021-03-01T17:53:48.389130505Z 73.8471523505953
L’opérateur with est très importante lors de l’appel de la fonction map.
Dans la syntaxe de base par défaut (sans l’opérateur with),
les colonnes qui ne font pas partie de la clé de groupe de la table d’entrée (_time, _start, _stop…)
et qui ne sont pas explicitement "mappées" sont supprimées :
|> map(fn: (r) => ({ pctspace: (r.used / (r.used + r.available)) * 100.0 }))Table: keys: [] pctspace:float ---------------------------- 73.84734021668079 73.84734021668079
L’opérateur with met à jour la colonne si elle existe, crée une nouvelle colonne si elle n’existe pas,
et inclut toutes les colonnes existantes de la table de sortie.
Colonnes calculées croisées (Cross computed columns)
Les colonnes calculées référençant des colonnes calculées ne peuvent pas être définies en un seul appel de la fonction map :
|> map(fn: (r) => ({ r with totalspace: r.used + r.available, pctspace: (r.used / r.totalspace) * 100.0 })) |> keep(columns: ["_time", "used", "totalspace","pctspace"])_time:time pctspace:float totalspace:float used:float ------------------------------ ---------------------------- ---------------------------- ---------------------------- 2021-03-02T18:33:36.041221773Z 40454348 29889216 2021-03-02T18:34:36.532166008Z 40454348 29889220
Dans ce contexte spécifique, la fonction map doit être appelée séquentiellement :
|> map(fn: (r) => ({ r with totalspace: r.used + r.available })) |> map(fn: (r) => ({ r with pctspace: (r.used / r.totalspace) * 100.0 })) |> keep(columns: ["_time", "used", "totalspace","pctspace"])_time:time pctspace:float totalspace:float used:float ------------------------------ ---------------------------- ---------------------------- ---------------------------- 2021-03-02T18:33:36.041221773Z 73.88386533877645 40454348 29889236 2021-03-02T18:34:36.532166008Z 73.88388511415386 40454348 29889244
Conditions, exists
Des conditions peuvent être utilisées dans la fonction map (if, else…) et l’opérateur exists est disponible :
import "math" … |> map(fn: (r) => ({ r with totalspace: r.used + r.available })) |> map(fn: (r) => ({ r with pctspace: (r.used / r.totalspace) * 100.0 })) |> aggregateWindow(every: 1m, fn: mean, column: "pctspace") |> map(fn: (r) => ({ r with pctspace: if exists r.pctspace then "${string(v: math.round(x: r.pctspace) )} %" else "N/A" })) |> keep(columns: ["_time", "used","pctspace"])_time:time pctspace:string ------------------------------ ---------------------- 2021-03-02T14:35:00.000000000Z 74 % 2021-03-02T14:36:00.000000000Z N/A
Fonctions d’agrégat personnalisées - reduce
Les fonctions Flux mean, max, min, sum, count… sont des bons raccourcis vers les agrégats,
mais seulement un agrégat peut être retourné.
from(bucket: "netdatatsdb/autogen") |> range(start: -1d) |> filter(fn: (r) => r._measurement == "vps_space" and r.host == "vpsfrsqlpac1" and (r._field == "used" or r._field == "available") ) |> pivot( rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value" ) |> count(column: "used")used:int -------------------------- 1428
Plusieurs résultats agrégés personnalisés peuvent être extraits avec la fonction reduce qui
retourne une ligne unique contenant les agrégats sans colonne _time.
from(bucket: "netdatatsdb/autogen") |> range(start: -1d) |> filter(fn: (r) => r._measurement == "vps_space" and r.host == "vpsfrsqlpac1" and (r._field == "used" or r._field == "available") ) |> pivot( rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value" ) |> map(fn: (r) => ({ r with totalspace: r.used + r.available })) |> map(fn: (r) => ({ r with pctspace: (r.used / r.totalspace) * 100.0 })) |> reduce(fn: (r, accumulator) => ( { count: accumulator.count + 1, max: if r.pctspace > accumulator.max then r.pctspace else accumulator.max }), identity: {count: 0, max: 0.0} ) |> keep(columns: ["count","max"])count:int max:float ---------------------------- ---------------------------- 1428 73.93648761809237
identity définit les valeurs initiales ainsi que les types de données (0 pour un integer, 0.0 pour un float).
Comme pour la fonction map, les conditions et l’opérateur exists sont autorisés.
On pourrait commenter : quel exemple stupide ! La fonction reduce calcule des agrégats disponibles avec des fonctions Flux natives,
pourquoi réinventer la roue ?
En effet, la fonction reduce devrait être utilisée pour des calculs d'agrégats pour lesquels aucune fonction native n’existe.
L’exemple ci-dessus peut être réécrit avec les fonctions natives count et max, une jointure est réalisée :
dataspace = from(bucket: "netdatatsdb/autogen") |> range(start: -1d) … datacnt = dataspace |> count(column:"pctspace") |> rename(columns: {"pctspace": "count"}) datamax = dataspace |> max(column:"pctspace") |> rename(columns: {"pctspace": "max"}) join( tables: {cnt: datacnt, max: datamax}, on: ["_measurement"] ) |> keep(columns: ["count", "max"]) |> yield()count:int max:float -------------------------- ---------------------------- 1428 73.93870246036347
L’exemple ci-dessus aurait été la requête InfluxQL suivante avec une sous-requête :
SELECT count(pctspace), max(pctspace)
FROM (SELECT (used / (used + available)) * 100 as pctspace
FROM "netdatatsdb.autogen.vps_space"
WHERE (host='vpsfrsqlpac1' and time > now() -1d)
)Améliorations notables de fonctions calendrier
hourSelection
Sélectionner des heures spécifiques d’une journée n’était pas possible avec InfluxQL.
Le langage Flux supporte les requêtes de type DatePart avec la fonction hourSelection pour ne retourner que les données
avec des valeurs _time dans une plage horaire indiquée.
from(bucket: "netdatatsdb/autogen")
|> range(start: -72h)
|> filter(fn: (r) => r._measurement == "vps_pcpumem" and
r.host == "vpsfrsqlpac1" and
r._field == "pcpu"
)
|> hourSelection(start: 8, stop: 18)
|> aggregateWindow(every: 1h, fn: mean)Fenêtrage des données par mois et années
Le langage Flux supporte le fenêtrage des données par mois (mo) et années (yr) : 1mo, 3mo, 1yr…
Cette fonctionnalité n’était pas non plus possible avec InfluxQL. Utile pour produire des KPI (Key Performance Indicators) par mois, trimestres, semestres, années.
|> aggregateWindow(every: 1mo, fn: mean)