
Introduction
Great new feature of the InfluxDB v2 time series databases and its Flux language : the gateways to SQL databases engines (PostgreSQL, MySQL, Microsoft SQL Server…). More databases drivers to come in future releases.
To retrieve and push data from/to SQL databases, 2 straightforward functions : sql.from and sql.to.
In this paper :
- InfluxDB time series data are enriched and dashboard variables are populated with reference data coming
from SQL databases using
sql.from. - Aggregated data are stored for long term purposes in SQL databases using
sql.to. Mechanism is described.
Specific considerations are addressed about data types conversions.
For beginners in the Flux language and/or used to InfluxQL, other publications are available on SQLPAC :
- InfluxDB - Moving from InfluxQL to Flux language
- InfluxDB v2 : Flux language, quick reference guide and cheat sheet
- InfluxDB : Flux language, advanced features (joins, pivot…)
The last cited article addresses how to perform joins using Flux language.
Managing connection settings (secrets)
Depending on the used driver (PostgreSQL, MySQL, MS SQL Server…), DSN connection string has different nomenclatures :
| PostgreSQL | |
| MySQL | |
| MS SQL Server | |
Full list of the available drivers DSN syntaxes : InfluxData - Driver dataSourceName examples
Avoid hard-coded connection strings in Flux scripts, define as much as possible all connection settings to databases (urls, user names, passwords, port…) in secrets
using influx client command line (cf Appendix about influx client usage).
Secrets are key-value pairs that contain sensitive information you want to control access to, such as API keys, passwords, or certificates…
Secrets are stored in this article in the InfluxDB server bolt database (startup server parameter : bolt-path = "/sqlpac/influxdb/srvifx2sqlpac/srvifxs2qlpac.bolt").
Creating secrets
The POSTGRES_DSN secret storing the full DSN is created using influx client :
$ influx secret update --key POSTGRES_DSN \
--value "postgresql://influxdb:""**********""@vpsfrsqlpac?port=30008&sslmode=disable"In the above example, password contains special characters, it is escaped using "".
Choice has been made here to store the full DSN in one secret, you may decide to create a secret per connection option :
$ influx secret update --key POSTGRES_HOST --value "vpsfrsqlpac"
$ influx secret update --key POSTGRES_USER --value "influxdb"
…Retrieving secrets in Flux scripts
In Flux scripts, a secret is retrieved using the secrets package
import "influxdata/influxdb/secrets"
POSTGRES_DSN = secrets.get(key: "POSTGRES_DSN")import "influxdata/influxdb/secrets"
POSTGRES_HOST = secrets.get(key: "POSTGRES_HOST")
POSTGRES_USER = secrets.get(key: "POSTGRES_USER")
…Querying SQL databases, sql.from
Very easy to query SQL databases using sql package and the from function, the code does not need comments :
import "sql" import "influxdata/influxdb/secrets" POSTGRES_DSN = secrets.get(key: "POSTGRES_DSN") sql.from( driverName: "postgres", dataSourceName: "${POSTGRES_DSN}", query: "SELECT name, totalmemory, \"date creation\" FROM vps WHERE name like \"vps%\"" )Result: _result Table: keys: [] name:string totalmemory:int date creation:time ---------------------- -------------------------- ------------------------------ vpsfrsqlpac1 4000 2020-09-18T00:00:00.000000000Z vpsfrsqlpac2 2000 2020-09-25T00:00:00.000000000Z vpsfrsqlpac3 2000 2020-09-29T00:00:00.000000000Z
Depending on the driver, data types translations from the source database to InfluxDB may differ. Pay attention to data types conversions.
| MySQL | InfluxDB | PostgreSQL | InfluxDB | |
|---|---|---|---|---|
| char, varchar | string | char, varchar | string | |
| float | float | double precision (float) | float | |
| integer | integer | integer | integer | |
| decimal | string | numeric | string | |
| date, time, timestamp | string | date, time, timestamp | time | |
| datetime | time |
Why querying SQL databases ? 2 common uses :
- Enriching data with reference data not available in measurements.
- Populating InfluxDB GUI dashboards variables.
Enriching data - Joins
Measurements do not store all needed data. Joins can be performed with reference data retrieved from SQL databases to enrich data.
An example : the vps_pcpumem measurement stores the used memory per host in the mem field.
vps_pcpumem,host=vpsfrsqlpac1 pcpu=22,mem=738 …
vps_pcpumem,host=vpsfrsqlpac1 pcpu=37,mem=772 …Total memory is not available in the measurement and we want to compute the used memory percentage. Knowing that total memory per host
is available in a PostgreSQL table : vps (name varchar(30), totalmemory int)
SELECT name, totalmemory FROM vpsname | totalmemory --------------+------------- vpsfrsqlpac1 | 4000 vpsfrsqlpac2 | 2000
Let’s perform a join to complete the objective :
import "influxdata/influxdb/secrets" POSTGRES_DSN = secrets.get(key: "POSTGRES_DSN") datavps = sql.from( driverName: "postgres", dataSourceName: "${POSTGRES_DSN}", query: "SELECT name as host, totalmemory FROM vps" ) datamem = from(bucket: "netdatatsdb/autogen") |> range(start: -1d) |> filter(fn: (r) => r._measurement == "vps_pcpumem" and r._field == "mem" and r.host == "vpsfrsqlpac1") join( tables: {vps:datavps, mem:datamem}, on: ["host"], method: "inner" ) |> map(fn: (r) => ({ r with pmem: (r._value / float(v: r.totalmemory)) * 100.0 })) |> rename(columns: { _value:"mem" }) |> keep(columns: ["_time","host","mem","pmem"])Result: _result Table: keys: [host] host:string _time:time mem:float pmem:float ---------------------- ------------------------------ ---------------------------- ---------------------------- vpsfrsqlpac1 2021-03-04T12:46:27.525578148Z 935 23.375 vpsfrsqlpac1 2021-03-04T12:47:27.886245623Z 989 24.725
In the map function, totalmemory is converted to float because
the source column datatype is integer. Using map function, data types must match in computations, otherwise a conflict error is raised.
Error: Runtime error @25:6-25:75: map: type conflict: float != int.Another approach : the conversion to float datatype is performed directly in the SQL query source.
…
datavps = sql.from(
driverName: "postgres",
dataSourceName: "${POSTGRES_DSN}",
query: "SELECT name as host, cast(totalmemory as float) FROM vps"
)
…
join(
tables: {vps:datavps, mem:datamem},
on: ["host"],
method: "inner"
)
|> map(fn: (r) => ({ r with pmem: (r._value / r.totalmemory) * 100.0 }))
…Populating InfluxDB GUI dashboards variables
SQL queries are very useful to populate the InfluxDB GUI dashboards variables with reference data : fields, dropdown lists…
In the below dashboard example, servers dropdown list is built from the vps PostgreSQL table :
A variable named server is created. The Flux script querying PostgreSQL is attached to the variable : in the Flux code,
the source column (name) is renamed to _value and only the column _value is returned
using keep function.
In a dashboard panel, filter is applied in the Flux query using the new v.server variable :
|> filter(fn: (r) => r["host"] == v.server)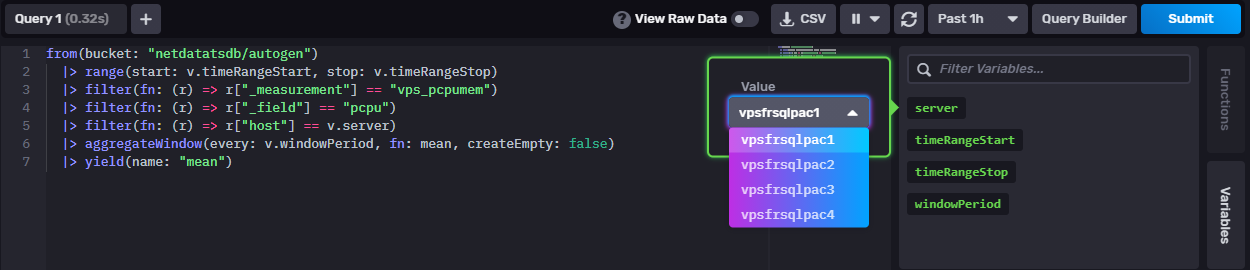
One quick note about Grafana : methodology is the same, the Flux query which retrieves data from the SQL database is attached to a variable.
Compared to InfluxDB GUI, in Grafana do not forget to call the yield function and keep in mind that
Flux queries are supported only as of Grafana 7.1.
import "sql"
import "influxdata/influxdb/secrets"
POSTGRES_DSN = secrets.get(key: "POSTGRES_DSN")
datavps = sql.from(
driverName: "postgres",
dataSourceName: "${POSTGRES_DSN}",
query: "SELECT name FROM vps"
)
|> rename(columns: { name:"_value" })
|> keep(columns: ["_value"])
|> yield()Writing to SQL databases, sql.to
InfluxDB sql.from function retrieves data from SQL databases. The function sql.to pushes
data to SQL databases. sql.from and sql.to syntaxes are analogous.
A very interesting feature to store long term aggregated data, especially when retention period is not infinite in InfluxDB servers.
In the code example below, data are pushed to the PostgreSQL table vpspmem, table already created :
import "sql"
import "influxdata/influxdb/secrets"
POSTGRES_DSN = secrets.get(key: "POSTGRES_DSN")
from(bucket: "netdatatsdb/autogen")
|> range(start: -1d)
|> filter(fn: (r) => r._measurement == "vps_pmem"
and r._field == "pmem"
and r.host == "vpsfrsqlpac2")
|> aggregateWindow(every: 1h, fn: mean, createEmpty: false)
|> rename(columns: {_value: "pmem", _time: "dth"})
|> keep(columns: ["host", "dth", "pmem"])
|> sql.to(
driverName: "postgres",
dataSourceName: "${POSTGRES_DSN}",
table: "vpspmem"
)CREATE TABLE vpspmem (
host varchar(30) not null,
dth timestamp not null,
pmem float not null
)Column names, data types and NULL/NOT NULL characteristics must match. An example error (NULL) :
! sql: transaction has already been committed or rolled back:
runtime error @14:6-18:6: to: pq:
null value in column "pmem" violates not-null constraintWhy creating the table first ? Behind the scenes, the sql.to function attempts to create the table if it does not exist,
but in the generated CREATE TABLE statement, string InfluxDB datatype is converted to TEXT datatype
which is not appropriate for indexing and maintenance, more accurate datatypes (varchar) are preferred :
- PostgreSQL :
2021-03-07 18:13:13.101 CET LOG: statement: CREATE TABLE IF NOT EXISTS vpspmem (dth TIMESTAMP,pmem FLOAT,host TEXT) - MySQL :
2021-03-05T17:41:47.737575Z 12 Query CREATE TABLE IF NOT EXISTS vpspmem (dth DATETIME,pmem FLOAT,host TEXT(16383))
How writes are performed ? For PostgreSQL and MySQL, prepared statements are sent within a transaction :
2021-03-05 18:31:18.154 CET LOG: statement: BEGIN READ WRITE
2021-03-05 18:31:18.157 CET LOG: statement: CREATE TABLE IF NOT EXISTS vpspmem (dth TIMESTAMP,pmem FLOAT,host TEXT)
2021-03-05 18:31:18.157 CET NOTICE: relation "vpspmem" already exists, skipping
2021-03-05 18:31:18.159 CET LOG: execute <unnamed>: INSERT INTO vpspmem (dth,pmem,host) VALUES ($1,$2,$3),($4,$5,$6), …
2021-03-05 18:31:18.159 CET DETAIL: parameters: $1 = '2021-03-04 16:00:00', $2 = '25.999999999999996', $3 = 'vpsfrsqlpac2',
$4 = '2021-03-04 17:00:00', $5 = '27.66186440677966', $6 = 'vpsfrsqlpac2', …
2021-03-05 18:31:18.160 CET LOG: statement: COMMITThe maximum number of columns or parameters in each prepared statement defaults to 10000 (batchsize).
If needed, batchsize parameter can be governed in the sql.to function :
|> sql.to(
driverName: "postgres",
dataSourceName: "${POSTGRES_DSN}",
table: "vpspmem",
batchsize: 50000
)Appendix - influx client
To be able to use influx client command line, config (url, token, org…) is defined before.
$ export INFLUX_CONFIGS_PATH=/sqlpac/influxdb/srvifx2sqlpac/configs
$ export INFLUX_ACTIVE_NAME=default/sqlpac/influxdb/srvifx2sqlpac/configs :
[default]
url = "https://vpsfrsqlpac:8086"
token = "K2YXbGhIJIjVhL…"
org = "sqlpac"
active = trueinflux client example usage :
$ influx secret listKey Organization ID PG_HOST 4dec7e867866cc2f PG_PASS 4dec7e867866cc2f PG_PORT 4dec7e867866cc2f PG_USER 4dec7e867866cc2f